Library to create and interogate local cache for Project Gutenberg

Project description
GutenbergPy

This package makes filtering and getting information from Project Gutenberg easier from python.
It's target audience is machine learning guys that need data for their project, but may be freely used by anybody.
The package:
- Generates a local cache (of all gutenberg informations) that you can interogate to get book ids. The Local cache may be sqlite (default) or mongodb (for wich you need to have installed the pymongodb packet)
- Downloads and cleans raw text from gutenberg books
The package has been tested with Python 3.6 on both Windows and Linux It is faster, smaller and less third-party intensive alternative to https://github.com/c-w/Gutenberg
About development: http://www.raduangelescu.com/gutenbergpy.html
Installation
pip install gutenbergpy
or just install it from source (it's all just python code):
git clone https://github.com/raduangelescu/gutenbergpy
python setup.py install
Usage
Downloading a text
import gutenbergpy.textget
After importing our module, we can download a text from gutenberg.
def usage_example():
# This gets a book by its gutenberg id number
raw_book = gutenbergpy.textget.get_text_by_id(2701) # with headers
clean_book = gutenbergpy.textget.strip_headers(raw_book) # without headers
return clean_book, raw_book
The code above can easily be used without the function declaration, this is simply for illustration.
cleaned_book, raw_book = usage_example()
# Cleaned Book
print(f'Example phrase from the cleaned book: {" ".join(str(cleaned_book[3000:3050]).split(" "))}')
# Raw Book
print(f'Example phrase from the raw book: {" ".join(str(raw_book[3000:3050]).split(" "))}')
The output of the code above is:
b'rgris.\n\nCHAPTER 93. The Castaway.\n\nCHAPTER 94. A S'
b'\n\n\n\nMOBY-DICK;\n\nor, THE WHALE.\n\nBy Herman Melville\n\n\n\nCONTENTS\n\nETYMOLOGY.\n\nEXTRACTS (Supplied by a Sub-Sub-Librarian).\n\nCHAPTER 1. Loomings.\n\nCHAPTER 2. The Carpet-Bag.\n\nCHAPTER 3. The Spouter-Inn.\n\nCHAPTER 4. The Counterpane.\n\nCHAPTER 5. Breakfast.\n\nCHAPTER 6. The Street.\n\nCHAPTER 7. The Chapel.\n\nCHAPTER 8. The Pulpit.\n\nCHAPTER 9. The Sermon.\n\nCHAPTER 10. A Bosom Friend.\n\nCHAPTER 11. Nightgown.\n\nCHAPTER 12. Biographical.\n\nCHAPTER 13. Wheelbarrow.\n\nCHAPTER 14. Nantucket.\n\nCHAPTER 15. Chowder.\n\nCHAPTER 16. The Ship.\n\nCHAPTER 17. The Ramadan.\n\nCHAPTER 18. His Mark.\n\nCHAPTER 19. The Prophet.\n\nCHAPTER 20. All Astir.\n\nCHAPTER 21. Going Aboard.\n\nCHAPTER 22. Merry Christmas.\n\nCHAPTER 23. The Lee Shore.\n\nCHAPTER 24. The Advocate.\n\nCHAPTER 25. Postscript.\n\nCHAPTER 26. Knights and Squires.\n\nCHAPTER 27. Knights and Squires.\n\nCHAPTER 28. Ahab.\n\nCHAPTER 29. Enter Ahab; to Him, Stubb.\n\nCHAPTER 30. The Pipe.\n\nCHAPTER 31. Queen Mab.\n\nCHAPTER 32. Cetology.\n\nCHAPTER 33. The Specksnyder.\n\nCHAPTER 34. Th'
They are both pretty messy, and will need to be cleaned prior to use for NLP etc.
The Raw book:
b'b\xe2\x80\x99s Supper.\r\n\r\nCHAPTER 65. The Whale as a Dish.\r'
b'\n\n\n\nMOBY-DICK;\n\nor, THE WHALE.\n\nBy Herman Melville\n\n\n\nCONTENTS\n\nETYMOLOGY.\n\nEXTRACTS (Supplied by a Sub-Sub-Librarian).\n\nCHAPTER 1. Loomings.\n\nCHAPTER 2. The Carpet-Bag.\n\nCHAPTER 3. The Spouter-Inn.\n\nCHAPTER 4. The Counterpane.\n\nCHAPTER 5. Breakfast.\n\nCHAPTER 6. The Street.\n\nCHAPTER 7. The Chapel.\n\nCHAPTER 8. The Pulpit.\n\nCHAPTER 9. The Sermon.\n\nCHAPTER 10. A Bosom Friend.\n\nCHAPTER 11. Nightgown.\n\nCHAPTER 12. Biographical.\n\nCHAPTER 13. Wheelbarrow.\n\nCHAPTER 14. Nantucket.\n\nCHAPTER 15. Chowder.\n\nCHAPTER 16. The Ship.\n\nCHAPTER 17. The Ramadan.\n\nCHAPTER 18. His Mark.\n\nCHAPTER 19. The Prophet.\n\nCHAPTER 20. All Astir.\n\nCHAPTER 21. Going Aboard.\n\nCHAPTER 22. Merry Christmas.\n\nCHAPTER 23. The Lee Shore.\n\nCHAPTER 24. The Advocate.\n\nCHAPTER 25. Postscript.\n\nCHAPTER 26. Knights and Squires.\n\nCHAPTER 27. Knights and Squires.\n\nCHAPTER 28. Ahab.\n\nCHAPTER 29. Enter Ahab; to Him, Stubb.\n\nCHAPTER 30. The Pipe.\n\nCHAPTER 31. Queen Mab.\n\nCHAPTER 32. Cetology.\n\nCHAPTER 33. The Specksnyder.\n\nCHAPTER 34. Th'
Query the cache
To do this you first need to create the cache (this is a one time thing per os, until you decide to redo it)
from gutenbergpy.gutenbergcache import GutenbergCache
#for sqlite
GutenbergCache.create()
#for mongodb
GutenbergCache.create(type=GutenbergCacheTypes.CACHE_TYPE_MONGODB)
for debugging/better control you have these boolean options on create
- refresh deletes the old cache
- download property downloads the rdf file from the gutenberg project
- unpack unpacks it
- parse parses it in memory
- cache writes the cache
GutenbergCache.create(refresh=True, download=True, unpack=True, parse=True, cache=True, deleteTemp=True)
for even better control you may set the GutenbergCacheSettings
- CacheFilename
- CacheUnpackDir
- CacheArchiveName
- ProgressBarMaxLength
- CacheRDFDownloadLink
- TextFilesCacheFolder
- MongoDBCacheServer
GutenbergCacheSettings.set( CacheFilename="", CacheUnpackDir="",
CacheArchiveName="", ProgressBarMaxLength="", CacheRDFDownloadLink="", TextFilesCacheFolder="", MongoDBCacheServer="")
After doing a create go grab a coffee, it will be over in about 5 minutes, depending on your internet speed and computer power (On a i7 with gigabit connection and ssd it finishes in about 1 minute)
Get the cache
#for mongodb
cache = GutenbergCache.get_cache(GutenbergCacheTypes.CACHE_TYPE_MONGODB)
#for sqlite
cache = GutenbergCache.get_cache()
Now you can do queries
Get the book Gutenberg unique indices by using this query function
Standard query fields:
- languages
- authors
- types
- titles
- subjects
- publishers
- bookshelves
- downloadtype
print(cache.query(downloadtype=['application/plain','text/plain','text/html; charset=utf-8']))
Or do a native query on the sqlite database
#python
cache.native_query("SELECT * FROM books")
#mongodb
cache.native_query({type:'Text'}}
For SQLITE custom queries, take a look at the SQLITE database scheme:
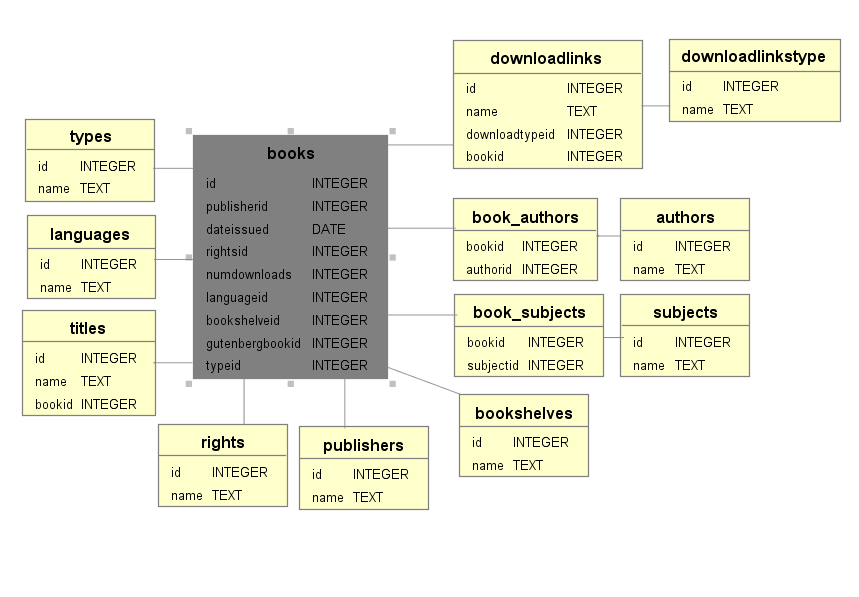
For MongoDB queries, you have all the books collection. Each book with the following fields:
- book(publisher, rights, language, book_shelf, gutenberg_book_id, date_issued, num_downloads, titles, subjects, authors, files ,type)
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Hashes for gutenbergpy-0.3.5-py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | b21e4a9fc97f23b57cd68aaa81b909187062c64b6a0b290fa53742f8fe849989 |
|
| MD5 | 6f1c804604e14395f3666a7c02992944 |
|
| BLAKE2b-256 | 64cc48d726295fa760a4c40ee0a8213d22c36435672298be1a0ec55a4743e0be |







