HistoQCxOMERO is an open-source quality control tool for digital pathology slides, forked to run on omero api

Project description
HistoQCxOMERO
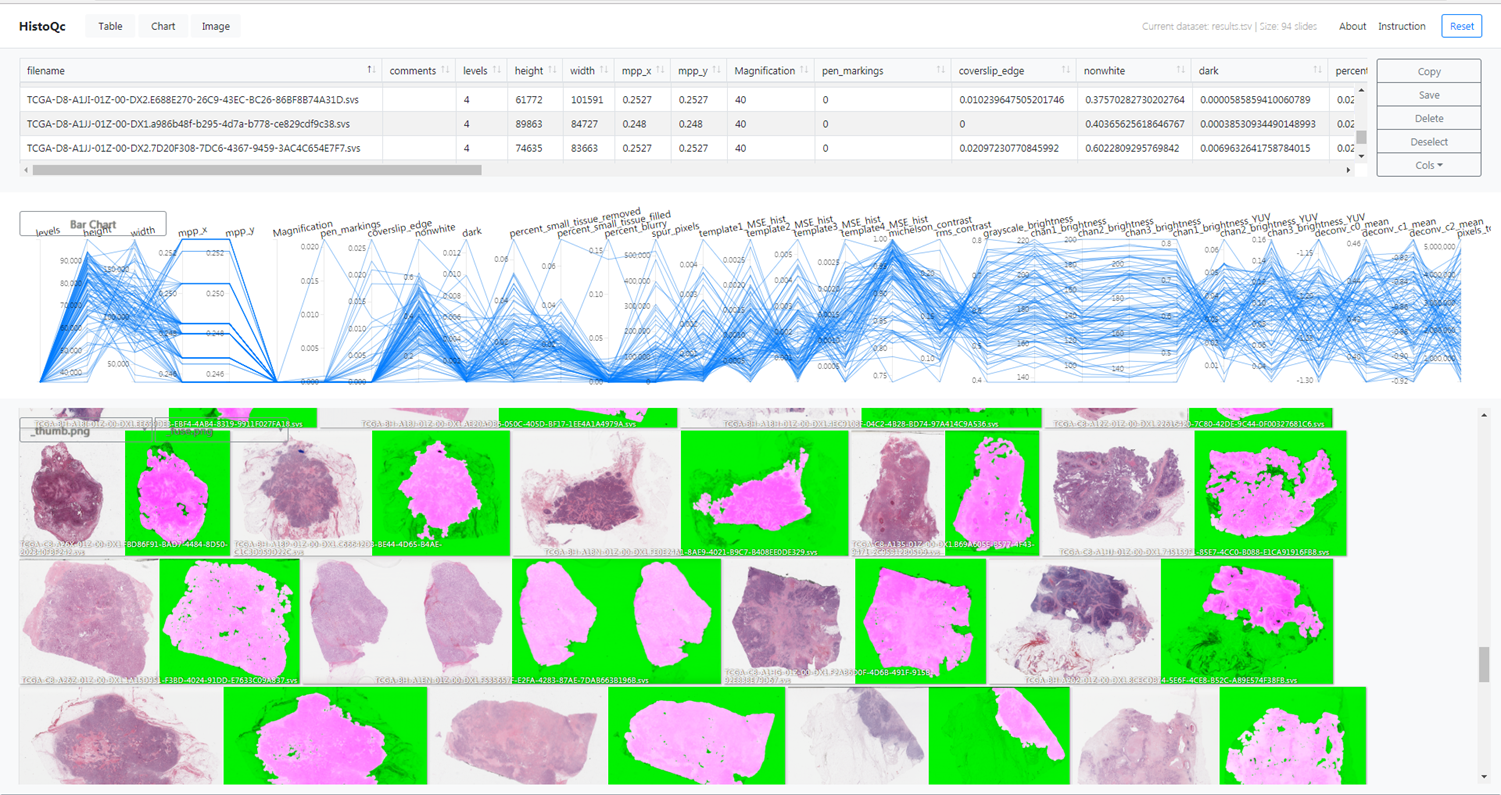
HistoQC is an open-source quality control tool for digital pathology slides
Requirements
Tested with Python 3.8 Note: the DockerFile installs Python 3.8, so if your goal is reproducibility you may want to take this into account
Requires:
- omero-py
- matplotlib
- numpy
- scipy
- skimage
- sklearn
- pytest (optional)
You can likely install the python requirements using something like (note python 3+ requirement):
pip3 install -r requirements.txt
The library versions have been pegged to the current validated ones. Later versions are likely to work but may not allow for cross-site/version reproducibility (typically a bad thing in quality control).
The most basic docker image can be created with the included Dockerfile.
Basic Usage
Running the pipeline is now done via a python module:
C:\Research\code\HistoQC>python -m histoqc --help
usage: __main__.py [-h] [-s SERVER] [-p PORT] [-u USER] [-w PASSWORD] [-o OUTDIR] [-P BASEPATH]
[-c CONFIG] [-f] [-b BATCH] [-n NPROCESSES] [--symlink TARGET_DIR]
object_id [object_id ...]
positional arguments:
object_id Project:id, Dataset:id, or id to select images by project id, dataset id, or image id respectively
or tsv file containing list of ids to analyze
optional arguments:
-h, --help show this help message and exit
-o OUTDIR, --outdir OUTDIR
outputdir, default ./histoqc_output_YYMMDD-hhmmss
-p BASEPATH, --basepath BASEPATH
base path to add to file names, helps when producing
data using existing output file as input
-c CONFIG, --config CONFIG
config file to use
-f, --force force overwriting of existing files
-b BATCH, --batch BATCH
break results file into subsets of this size
-n NPROCESSES, --nprocesses NPROCESSES
number of processes to launch
--symlink TARGET_DIR create symlink to outdir in TARGET_DIR
HistoQC now has a httpd server which allows for improved result viewing, it can be accessed like so:
C:\Research\code\HistoQC>python -m histoqc.ui --help
usage: __main__.py [-h] [--bind ADDRESS] [--port PORT] [--deploy OUT_DIR]
[data_directory]
positional arguments:
data_directory Specify the data directory [default:current directory]
optional arguments:
-h, --help show this help message and exit
--bind ADDRESS, -b ADDRESS
Specify alternate bind address [default: all
interfaces]
--port PORT Specify alternate port [default: 8000]
--deploy OUT_DIR Write UI to OUT_DIR
Lastly, supplied configuration files can be viewed and modified like so:
C:\Research\code\HistoQC>python -m histoqc.config --help
usage: __main__.py [-h] [--list] [--show NAME]
show example config
optional arguments:
-h, --help show this help message and exit
--list list available configs
--show NAME show named example config
If you would like, you can install HistoQC into your system by using
git clone https://github.com/choosehappy/HistoQC.git
cd HistoQC
python -m pip install --upgrade pip # (optional) upgrade pip to newest version
pip install -r requirements.txt # install pinned versions of packages
pip install .
Installed or simply git-cloned, a typical command line for running the tool thus looks like:
python -m histoqc -c v2.1 -n 3 "*.svs"
which will use 3 process to operate on all svs files using the named configuration file config_v2.1.ini from the config directory.
Alternatively one can specify their own modified config file using an absolute or relative filename:
python -m histoqc.config --show light > mylight.ini
python -m histoqc -c ./mylight.ini -n 3 "*.svs"
Afterward completion of slide processing you can view the results in your web-browser simply by following the directions after typing:
python -m histoqc.ui
Which will likely say something like:
HistoQC data directory: 'D:\temp\HistoQC'
Serving HistoQC UI on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
Allowing you to browse to http://localhost:8000/ to select your results.tsv file.
In case of errors, HistoQC can be run with the same output directory and will begin where it left off, identifying completed images by the presence of an existing directory.
This can also be done remotely, but is a bit more complex, see advanced usage.
Configuration modifications
HistoQC's performance is significantly improved if you select an appropriate configuration file as a starting point and modify it to suit your specific use case.
If you would like to see a list of provided config files to start you off, you can type
python -m histoqc.config --list
and then you can select one and write it to file like so for your modification and tuning:
python -m histoqc.config --show ihc > myconfig_ihc.ini
Advanced Usage
See wiki
Notes
Information from HistoQC users appears below:
- the new Pannoramic 1000 scanner, objective-magnification is given as 20, when a 20x objective lense and a 2x aperture boost is used, i.e. image magnification is actually 40x. While their own CaseViewer somehow determines that a boost exists and ends up with 40x when objective-magnification in Slidedat.ini is at 20, openslide and bioformats give 20x.
1.1. When converted to svs by CaseViewer, the MPP entry in ImageDescription meta-parameter give the average of the x and y mpp. Both values are slightly different for the new P1000 and can be found in meta-parameters of svs as tiff.XResolution and YResolution (inverse values, so have to be converted, also respecting ResolutionUnit as centimeter or inch
Citation
If you find this software useful, please drop me a line and/or consider citing it:
"HistoQC: An Open-Source Quality Control Tool for Digital Pathology Slides", Janowczyk A., Zuo R., Gilmore H., Feldman M., Madabhushi A., JCO Clinical Cancer Informatics, 2019
Manuscript available here
“Assessment of a computerized quantitative quality control tool for kidney whole slide image biopsies”, Chen Y., Zee J., Smith A., Jayapandian C., Hodgin J., Howell D., Palmer M., Thomas D., Cassol C., Farris A., Perkinson K., Madabhushi A., Barisoni L., Janowczyk A., Journal of Pathology, 2020
Manuscript available here
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.







