Knowledge Enhanced Neural Networks

Project description
KENN: Knowledge Enhanced Neural Networks
KENN2 (Knowledge Enhanced Neural Networks 2.0) is a library for Python 3 built on top of TensorFlow 2 that allows you to modify neural network models by providing logical knowledge in the form of a set of universally quantified FOL clauses. It does so by adding a new final layer, called Knowledge Enhancer (KE), to the existing neural network. The KE changes the original predictions of the standard neural network enforcing the satisfaction of the knowledge. Additionally, it contains clause weights, learnable parameters which represent the strength of each clause.
NB: version 1.0 of KENN was released for Python 2.7 and TensorFlow 1.x and it is available at KENN v1.0. Notice that this version is not backward compatible. Additionally, this implementation of KENN can work with relational domains, meaning that one can use also binary predicates to express logical rules which involve the relationship between two objects.
This is an implementation of the model presented in our paper: Knowledge Enhanced Neural Networks.
If you use this software for academic research, please, cite our work using the following BibTeX:
@InProceedings{10.1007/978-3-030-29908-8_43,
author="Daniele, Alessandro
and Serafini, Luciano",
editor="Nayak, Abhaya C.
and Sharma, Alok",
title="Knowledge Enhanced Neural Networks",
booktitle="PRICAI 2019: Trends in Artificial Intelligence",
year="2019",
publisher="Springer International Publishing",
address="Cham",
pages="542--554",
isbn="978-3-030-29908-8"
}
Installation
KENN can be installed using pip:
pip install KENN2
Getting started: A simple model with Keras and KENN
KENN 2.0 allows you to easily add KENN layers to Keras models. To add the knowledge to a keras model it is sufficient to add a new layer:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# Import parser for the knowledge file
from KENN2.parsers import unary_parser
model = keras.Sequential([
Dense(100, activation="relu", name="layer1"), Dense(50, activation="relu", name="layer2"), # Last NN layer
Dense(5, activation="linear", name="layer3"), # Added the Knowledge Enhancer
unary_parser(’knowledge file path’,
activation=tf.nn.sigmoid)
])
# Compile the model
model.compile(optimizer=’adam’, loss=’mean squared error’)
Example explained
In the previous example, we apply only two changes to the standard TensorFlow code. Following, the details.
1. Import a parser for the knowledge base.
This first change is trivial: we need to import the parser of the knwoledge:
from KENN2.parsers import unary_parser
2. Add KENN layer
unary_parser(’knowledge file path’,activation=tf.nn.sigmoid)
The unary_parser function takes as input the path of the file containing the logical constraints and the activation function to be used. It returns a Keras layer which can be stacked on top of a Keras model. Such layer updates the predictions based on the content of the knowledge base file.
Following, an example of knowledge base file:
Dog,Cat,Animal,Car,Truck,Chair
1.5:nDog,Animal
_:nCat,Animal
2.0:nDog,nCat
_:nCar,Animal
_:nAnimal,Dog,Cat
The first row contains a list of predicates separated with a comma with no spaces. Each predicate must start with a capital letter. The second row must be empty. The other rows contain the clauses. Each clause is in a separate row and must be written respecting this properties:
- Logical disjunctions are represented with commas;
- If a literal is negated, it must be preceded by the lowercase 'n';
- They must contain only predicates specified in the first row;
- There shouldn't be spaces.
Additionally, each clause must be preceded by a positive weight that represents the strength of the clause. More precisely, the weight could be a numeric value or an underscore: in the first case, the weight is fixed and determined by the specified value, in the second case the weight is learned during training. For example, the third line represents the clause
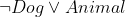
Working with relational data
KENN 2.0 provides extra features to work with relational data, meaning that it supports also clauses containing binary predicates. Typical cases of relational data can be a Citation Network of scientific publications or a Social Network: in those examples the binary predicates would be Cite(x,y), and Friend(x,y) respectively, which represent the edges of the graph. In the following, a very simple presentation of KENN for relational data. For a deeper explanation, please check our tutorial on the CiteSeer dataset.
Similarly to the previous case, the first step is to import a parser. This time the parser needs to read a knowledge file which contains binary predicates:
from KENN2.parsers import relational_parser
As before, the relational_parser is a function which returns a layer that injects the logic into the model.
N.B: Currently, KENN is not compatible with Keras Sequential models. It can still be used without any issues using standard Tensorflow code.
The content of the knowledge file is similar to the previous case, with some notable changes:
In the previous case, the first row was a list of predicates. Now, there are two rows: the first containing the list of unary predicates, the second containing the binary predicates.
The clauses are also split in two groups: the first group contains only unary predicates, the second both unary and binary predicates. The two groups are separated by a row containing the > symbol.
Unary predicates are defined on a single variable (e.g. Dog(x)), binary predicates on two variables separated by a dot (e.g. Friends(x.y)). Following an example of a relational knowledge file:
Smoker,Cancer
Friends
_:nSmoker(x),Cancer(x)
>
_:nFriends(x.y),nSmoker(x),Smoker(y)
The first row specifies that there are two unary predicates: Smoker and Cancer. Second row specifies the binary predicates, which in this case is one: Friends. The first clause encodes the fact that a smoker also has cancer (note that the rules does not represent hard constraints) and the second, which contains also the binary predicate, expresses the idea that friends tend to have similar smoking habits.
License
Copyright (c) 2019, Daniele Alessandro, Mazzieri Riccardo, Serafini Luciano All rights reserved.
Licensed under the BSD 3-Clause License.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.







