Neural building blocks for speaker diarization

Project description
Using pyannote.audio open-source toolkit in production?
Make the most of it thanks to our consulting services.
pyannote.audio speaker diarization toolkit
pyannote.audio is an open-source toolkit written in Python for speaker diarization. Based on PyTorch machine learning framework, it comes with state-of-the-art pretrained models and pipelines, that can be further finetuned to your own data for even better performance.
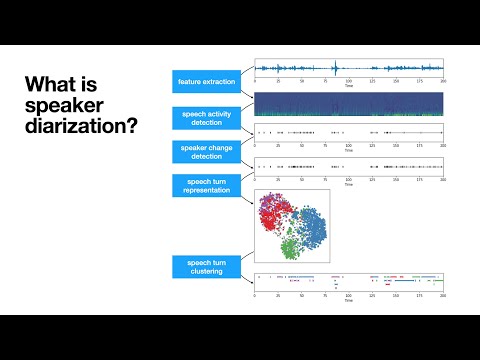
TL;DR
- Install
pyannote.audiowithpip install pyannote.audio - Accept
pyannote/segmentation-3.0user conditions - Accept
pyannote/speaker-diarization-3.1user conditions - Create access token at
hf.co/settings/tokens.
from pyannote.audio import Pipeline
pipeline = Pipeline.from_pretrained(
"pyannote/speaker-diarization-3.1",
use_auth_token="HUGGINGFACE_ACCESS_TOKEN_GOES_HERE")
# send pipeline to GPU (when available)
import torch
pipeline.to(torch.device("cuda"))
# apply pretrained pipeline
diarization = pipeline("audio.wav")
# print the result
for turn, _, speaker in diarization.itertracks(yield_label=True):
print(f"start={turn.start:.1f}s stop={turn.end:.1f}s speaker_{speaker}")
# start=0.2s stop=1.5s speaker_0
# start=1.8s stop=3.9s speaker_1
# start=4.2s stop=5.7s speaker_0
# ...
Highlights
- :hugs: pretrained pipelines (and models) on :hugs: model hub
- :exploding_head: state-of-the-art performance (see Benchmark)
- :snake: Python-first API
- :zap: multi-GPU training with pytorch-lightning
Documentation
- Changelog
- Frequently asked questions
- Models
- Available tasks explained
- Applying a pretrained model
- Training, fine-tuning, and transfer learning
- Pipelines
- Available pipelines explained
- Applying a pretrained pipeline
- Adapting a pretrained pipeline to your own data
- Training a pipeline
- Contributing
- Adding a new model
- Adding a new task
- Adding a new pipeline
- Sharing pretrained models and pipelines
- Blog
- Videos
- Introduction to speaker diarization / JSALT 2023 summer school / 90 min
- Speaker segmentation model / Interspeech 2021 / 3 min
- First releaase of pyannote.audio / ICASSP 2020 / 8 min
Benchmark
Out of the box, pyannote.audio speaker diarization pipeline v3.1 is expected to be much better (and faster) than v2.x.
Those numbers are diarization error rates (in %):
| Benchmark | v2.1 | v3.1 | Premium |
|---|---|---|---|
| AISHELL-4 | 14.1 | 12.3 | 11.9 |
| AliMeeting (channel 1) | 27.4 | 24.5 | 22.5 |
| AMI (IHM) | 18.9 | 18.8 | 16.6 |
| AMI (SDM) | 27.1 | 22.6 | 20.9 |
| AVA-AVD | 66.3 | 50.0 | 39.8 |
| CALLHOME (part 2) | 31.6 | 28.4 | 22.2 |
| DIHARD 3 (full) | 26.9 | 21.4 | 17.2 |
| Ego4D (dev.) | 61.5 | 51.2 | 43.8 |
| MSDWild | 32.8 | 25.4 | 19.8 |
| REPERE (phase2) | 8.2 | 7.8 | 7.6 |
| VoxConverse (v0.3) | 11.2 | 11.2 | 9.4 |
Diarization error rate (in %)
Citations
If you use pyannote.audio please use the following citations:
@inproceedings{Plaquet23,
author={Alexis Plaquet and Hervé Bredin},
title={{Powerset multi-class cross entropy loss for neural speaker diarization}},
year=2023,
booktitle={Proc. INTERSPEECH 2023},
}
@inproceedings{Bredin23,
author={Hervé Bredin},
title={{pyannote.audio 2.1 speaker diarization pipeline: principle, benchmark, and recipe}},
year=2023,
booktitle={Proc. INTERSPEECH 2023},
}
Development
The commands below will setup pre-commit hooks and packages needed for developing the pyannote.audio library.
pip install -e .[dev,testing]
pre-commit install
Test
pytest
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Hashes for pyannote.audio-3.1.1-py2.py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 52f86cba990c0afaffecd7ecb84aff79709a51923462ae8a44d6ac4d2010836a |
|
| MD5 | 0cc7f996be23afc687ee580fc0b5bdc4 |
|
| BLAKE2b-256 | f511611c32f7b7894ba588ade502525d0130f3e731d15f925e9f2a1ae66c8680 |







