Streamline your Kafka data processing, this tool aims to standardize streaming data from multiple Kafka clusters. With a pub-sub approach, multiple functions can easily subscribe to incoming messages, serialization can be specified per topic, and data is automatically processed by data sink functions.

Project description



Snapstream

Snapstream provides a data-flow model to simplify development of stateful streaming applications.
Installation
pip install snapstream
Usage
We snap iterables to user functions, and process them in parallel when we call stream:
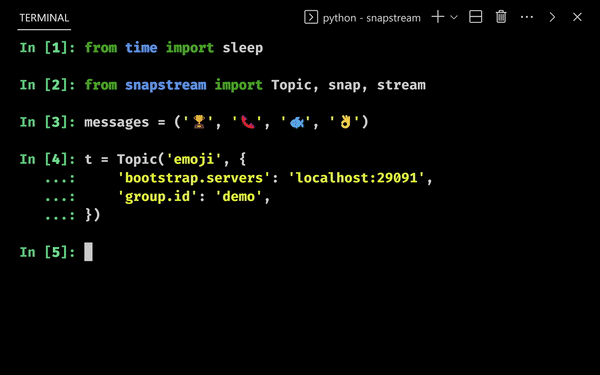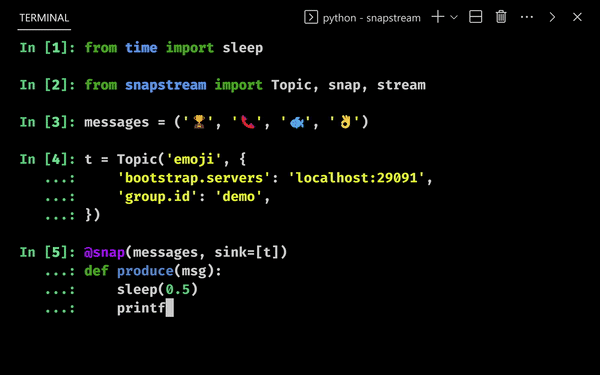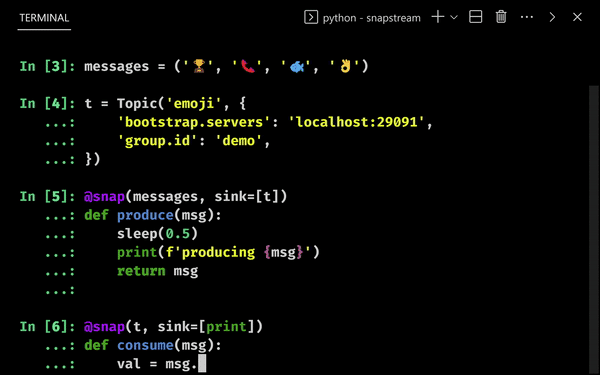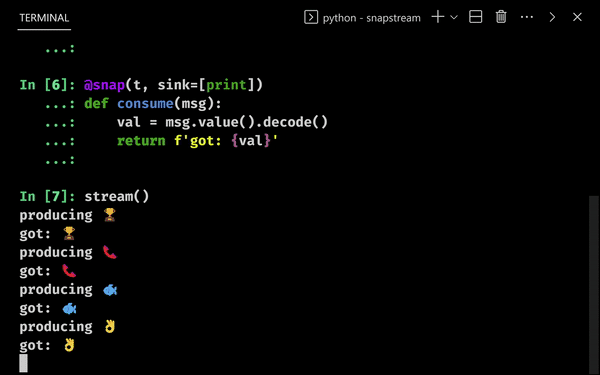
We pass the callable print to print out the return value. Multiple iterables and sinks can be passed.
from snapstream import snap, stream
@snap(range(5), sink=[print])
def handler(msg):
yield f'Hello {msg}'
stream()
Hello 0
Hello 1
Hello 2
Hello 3
Hello 4
To try it out for yourself, spin up a local kafka broker with docker-compose.yml, using localhost:29091 to connect:
docker compose up broker -d
Use the cli tool to inspect Topic/Cache:
snapstream topic emoji --offset -2
>>> timestamp: 2023-04-28T17:31:51.775000+00:00
>>> offset: 0
>>> key:
🏆
Features
snapstream.snap: bind streams (iterables) and sinks (callables) to user defined handler functionssnapstream.stream: start streamingsnapstream.Topic: consume from (iterable), and produce to (callable) kafka using confluent-kafkasnapstream.Cache: store data to disk using rocksdictsnapstream.Conf: set global kafka configuration (can be overridden per topic)snapstream.codecs.AvroCodec: serialize and deserialize avro messagessnapstream.codecs.JsonCodec: serialize and deserialize json messages
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Hashes for snapstream-1.0.0-py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | f5323d0c7f5c94a459f7dfed460514b5e823784b65155f003b289b7c27603358 |
|
| MD5 | f0169ee279c281b6028d1dbb25d05fdb |
|
| BLAKE2b-256 | 740f9bd2576285f13a92facdf08a8f03a9b6b2ff4fcf0abd40d319a14f3ccc45 |







