Feature set algebra for linguistics


Project description




Features is a simple implementation of feature set algebra in Python.
Linguistic analyses commonly use sets of binary or privative features to refer to different groups of linguistic objects: for example a group of phonemes that share some phonological features like [-consonantal, +high] or a set of morphemes that occur in context of a specific person/number combination like [-participant, GROUP]. Usually, the features are applied in a way such that only some of their combinations are valid, while others are impossible (i.e. refer to no object) – for example [+high, +low], or [-participant, +speaker].
With this package, such feature systems can be defined with a simple contingency table definition (feature matrix) and stored under a section name in a simple clear-text configuration file. Each feature system can then be loaded by its name and provides its own FeatureSet subclass that implements all comparisons and operations between its feature sets according to the given definition (compatibility, entailment, intersection, unification, etc.).
Features creates the complete lattice structure between the possible feature sets of each feature system and lets you navigate and visualize their relations using the Graphviz graph layout library.
Installation
This package runs under Python 2.7 and 3.3+, use pip to install:
$ pip install featuresThis will also install the concepts package from PyPI providing the Formal Concept Analysis (FCA) algorithms on which this package is based.
Features is essentially a convenience wrapper around the FCA-functionality of concepts.
Systems
Features includes some predefined feature systems that you can try out immediately. To load a feature system, pass its name to features.FeatureSystem:
>>> import features
>>> fs = features.FeatureSystem('plural')
>>> fs
<FeatureSystem('plural') of 6 atoms 22 featuresets>The built-in feature systems are defined in the config.ini file in the package directory (usually, this will be Lib/site-packages/concepts in your Python directory).
The definition of a feature system is stored in its context object:
>>> print(fs.context) # doctest: +ELLIPSIS
<Context object mapping 6 objects to 10 properties at 0x...>
|+1|-1|+2|-2|+3|-3|+sg|+pl|-sg|-pl|
1s|X | | |X | |X |X | | |X |
1p|X | | |X | |X | |X |X | |
2s| |X |X | | |X |X | | |X |
2p| |X |X | | |X | |X |X | |
3s| |X | |X |X | |X | | |X |
3p| |X | |X |X | | |X |X | |
>>> fs.context.objects
('1s', '1p', '2s', '2p', '3s', '3p')
>>> fs.context.properties
('+1', '-1', '+2', '-2', '+3', '-3', '+sg', '+pl', '-sg', '-pl')
>>> fs.context.bools # doctest: +NORMALIZE_WHITESPACE
[(True, False, False, True, False, True, True, False, False, True),
(True, False, False, True, False, True, False, True, True, False),
(False, True, True, False, False, True, True, False, False, True),
(False, True, True, False, False, True, False, True, True, False),
(False, True, False, True, True, False, True, False, False, True),
(False, True, False, True, True, False, False, True, True, False)]It basically provies a mapping from objects to features and vice versa. Check the documentation of concepts for further information on its full functionality.
>>> fs.context.intension(['1s', '1p']) # common features?
('+1', '-2', '-3')
>>> fs.context.extension(['-3', '+sg']) # common objects?
('1s', '2s')Feature sets
All feature system contain a contradicting feature set with all features that refers to no object:
>>> fs.infimum
FeatureSet('+1 -1 +2 -2 +3 -3 +sg +pl -sg -pl')
>>> fs.infimum.concept.extent
()As well as a maximally general tautological feature set with no features referring to all objects:
>>> fs.supremum
FeatureSet('')
>>> fs.supremum.concept.extent
('1s', '1p', '2s', '2p', '3s', '3p')Use the feature system to iterate over all defined feature sets in shortlex extent order:
>>> for f in fs:
... print('%s %s' % (f, f.concept.extent))
[+1 -1 +2 -2 +3 -3 +sg +pl -sg -pl] ()
[+1 +sg] ('1s',)
[+1 +pl] ('1p',)
[+2 +sg] ('2s',)
[+2 +pl] ('2p',)
[+3 +sg] ('3s',)
[+3 +pl] ('3p',)
[+1] ('1s', '1p')
[-3 +sg] ('1s', '2s')
[-2 +sg] ('1s', '3s')
[-3 +pl] ('1p', '2p')
[-2 +pl] ('1p', '3p')
[+2] ('2s', '2p')
[-1 +sg] ('2s', '3s')
[-1 +pl] ('2p', '3p')
[+3] ('3s', '3p')
[+sg] ('1s', '2s', '3s')
[+pl] ('1p', '2p', '3p')
[-3] ('1s', '1p', '2s', '2p')
[-2] ('1s', '1p', '3s', '3p')
[-1] ('2s', '2p', '3s', '3p')
[] ('1s', '1p', '2s', '2p', '3s', '3p')The string representations will show the smallest possible notation for each feature set by default (shortlex minimum). The full representation is also available (and an extent-based representation):
>>> fs('1sg').string
'+1 +sg'
>>> fs('1sg').string_maximal
'+1 -2 -3 +sg -pl'
>>> fs('1sg').string_extent
'1s'To use the maximal representation for __str__, put str_maximal = true into the configuration (see below).
Retrieval
You can call the feature system with an iterable of features to retrieve one of its feature sets:
>>> fs(['+1', '+sg'])
FeatureSet('+1 +sg')Usually, it is more convenient to let the system extract the features from a string:
>>> fs('+1 +sg')
FeatureSet('+1 +sg')Leading plusses can be omitted. Spaces are optional. Case, order, and duplication of features are ignored.
>>> fs('2 pl')
FeatureSet('+2 +pl')
>>> fs('SG3sg')
FeatureSet('+3 +sg')Note that commas are not allowed inside the string.
Uniqueness
Feature sets are singletons. The constructor is also idempotent:
>>> fs('1sg') is fs('1sg')
True
>>> fs(fs('1sg')) is fs('1sg')
TrueAll different possible ways to notate a feature set map to the same instance:
>>> fs('+1 -2 -3 -sg +pl') is fs('1pl')
True
>>> fs('+sg') is fs('-pl')
TrueNotations are equivalent, when they refer to the same set of objects (have the same extent).
Comparisons
Compatibility tests:
>>> fs('+1').incompatible_with(fs('+3'))
True
>>> fs('sg').complement_of(fs('pl'))
True
>>> fs('-1').subcontrary_with(fs('-2'))
True
>>> fs('+1').orthogonal_to(fs('+sg'))
TrueSet inclusion (subsumption):
>>> fs('') < fs('-3') <= fs('-3') < fs('+1') < fs('1sg')
TrueOperations
Intersection (join, generalization, closest feature set that subsumes the given ones):
>>> fs('1sg') % fs('2sg') # common features, or?
FeatureSet('-3 +sg')Intersect an iterable of feature sets:
>>> fs.join([fs('+1'), fs('+2'), fs('1sg')])
FeatureSet('-3')Union (meet, unification, closest feature set that implies the given ones):
>>> fs('-1') ^ fs('-2') # commbined features, and?
FeatureSet('+3')Unify an iterable of feature sets:
>>> fs.meet([fs('+1'), fs('+sg'), fs('-3')])
FeatureSet('+1 +sg')Relations
Immediately implied/subsumed neighbors.
>>> fs('+1').upper_neighbors
[FeatureSet('-3'), FeatureSet('-2')]
>>> fs('+1').lower_neighbors
[FeatureSet('+1 +sg'), FeatureSet('+1 +pl')]Complete set of implied/subsumed neighbors.
>>> list(fs('+1').upset())
[FeatureSet('+1'), FeatureSet('-3'), FeatureSet('-2'), FeatureSet('')]
>>> list(fs('+1').downset()) # doctest: +NORMALIZE_WHITESPACE
[FeatureSet('+1'),
FeatureSet('+1 +sg'), FeatureSet('+1 +pl'),
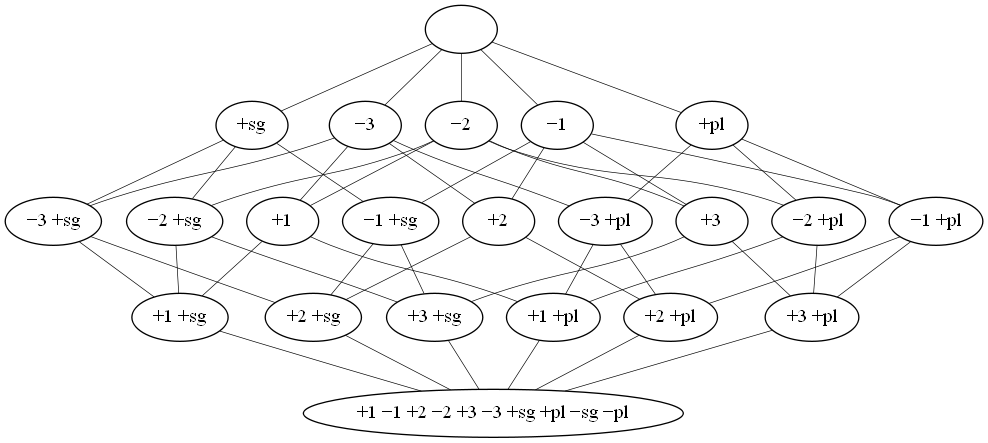
FeatureSet('+1 -1 +2 -2 +3 -3 +sg +pl -sg -pl')]Visualization
Create a graph of the feature system lattice.
>>> dot = fs.graphviz()
>>> print(dot.source) # doctest: +ELLIPSIS, +NORMALIZE_WHITESPACE
// <FeatureSystem('plural') of 6 atoms 22 featuresets>
digraph plural {
graph [margin=0]
edge [arrowtail=none dir=back penwidth=.5]
f0 [label="+1 −1 +2 −2 +3 −3 +sg +pl −sg −pl"]
f1 [label="+1 +sg"]
f1 -> f0
f2 [label="+1 +pl"]
f2 -> f0
...
Check the documentation of this package for details on the resulting object.
Definition
If you do not need to save your definition, you can directly create a system from an ASCII-art style table:
>>> fs = features.make_features('''
... |+male|-male|+adult|-adult|
... man | X | | X | |
... woman| | X | X | |
... boy | X | | | X |
... girl | | X | | X |
... ''', str_maximal=False)
>>> fs # doctest: +ELLIPSIS
<FeatureSystem object of 4 atoms 10 featuresets at 0x...>
>>> for f in fs:
... print('%s %s' % (f, f.concept.extent))
[+male -male +adult -adult] ()
[+male +adult] ('man',)
[-male +adult] ('woman',)
[+male -adult] ('boy',)
[-male -adult] ('girl',)
[+adult] ('man', 'woman')
[+male] ('man', 'boy')
[-male] ('woman', 'girl')
[-adult] ('boy', 'girl')
[] ('man', 'woman', 'boy', 'girl')Note that the strings representing the objects and features need to be disjoint and features cannot be in substring relation.
To load feature systems by name, create an INI-file with your configurations, for example:
# phonemes.ini - define distinctive features
[vowels]
description = Distinctive vowel place features
str_maximal = true
context =
|+high|-high|+low|-low|+back|-back|+round|-round|
i| X | | | X | | X | | X |
y| X | | | X | | X | X | |
ɨ| X | | | X | X | | | X |
u| X | | | X | X | | X | |
e| | X | | X | | X | | X |
ø| | X | | X | | X | X | |
ʌ| | X | | X | X | | | X |
o| | X | | X | X | | X | |
æ| | X | X | | | X | | X |
œ| | X | X | | | X | X | |
ɑ| | X | X | | X | | | X |
ɒ| | X | X | | X | | X | |Add your config file, overriding existing sections with the same name:
>>> features.add_config('docs/phonemes.ini')If the filename is relative, it is resolved relative to the file where the add method was called. Check the documentation of the fileconfig package for details.
Load your feature system:
>>> fs = features.FeatureSystem('vowels')
>>> fs
<FeatureSystem('vowels') of 12 atoms 55 featuresets>Retrieve feature sets, extents and intents:
>>> print(fs('+high'))
[+high -low]
>>> print('high round = %s, %s' % fs('high round').concept.extent)
high round = y, u
>>> print('i, e, o = %s' % fs.lattice[('i', 'e', 'o')].intent)
i, e, o = -lowLogical relations between feature pairs (excluding orthogonal pairs):
>>> print(fs.context.relations()) # doctest: +NORMALIZE_WHITESPACE
+high complement -high
+low complement -low
+back complement -back
+round complement -round
+high incompatible +low
+high implication -low
+low implication -high
-high subcontrary -lowUsage example
Make a paradigm for the present and past tense forms of the English copula to be and compute the common features for all different word forms.
Define a feature system with the meanings for the paradigm cells.
>>> context = '''
... |+1|-1|+2|-2|+3|-3|+sg|+pl|+pst|-pst|
... 1sg.pres| X| | | X| | X| X| | | X|
... 1pl.pres| X| | | X| | X| | X| | X|
... 2sg.pres| | X| X| | | X| X| | | X|
... 2pl.pres| | X| X| | | X| | X| | X|
... 3sg.pres| | X| | X| X| | X| | | X|
... 3pl.pres| | X| | X| X| | | X| | X|
... 1sg.past| X| | | X| | X| X| | X| |
... 1pl.past| X| | | X| | X| | X| X| |
... 2sg.past| | X| X| | | X| X| | X| |
... 2pl.past| | X| X| | | X| | X| X| |
... 3sg.past| | X| | X| X| | X| | X| |
... 3pl.past| | X| | X| X| | | X| X| |'''
>>> fs = features.make_features(context)
>>> cellmeanings = fs.atomsEnter the word forms for each cell.
>>> cellforms = [
... 'am', 'are',
... 'are', 'are',
... 'is', 'are',
...
... 'was', 'were',
... 'were', 'were',
... 'was', 'were']Create the paradigm as ordered mapping from meaning to form.
>>> from collections import OrderedDict
>>> paradigm = OrderedDict(zip(cellmeanings, cellforms))Pretty-print the meaning -> word form mapping.
>>> for meaning, form in paradigm.items():
... print('%s | %s' % (meaning.string_extent, form))
1sg.pres | am
1pl.pres | are
2sg.pres | are
2pl.pres | are
3sg.pres | is
3pl.pres | are
1sg.past | was
1pl.past | were
2sg.past | were
2pl.past | were
3sg.past | was
3pl.past | wereCreate a correspondence from each word form to the list of cell meanings where it occurs.
>>> occurrences = OrderedDict()
>>> for meaning in paradigm:
... form = paradigm[meaning]
... occurrences.setdefault(form, []).append(meaning)Pretty-print the form -> occurrences mapping.
>>> for form in occurrences:
... meanings = occurrences[form]
... labels = ', '.join(m.string_extent for m in meanings)
... print('%4s | %s' % (form, labels))
am | 1sg.pres
are | 1pl.pres, 2sg.pres, 2pl.pres, 3pl.pres
is | 3sg.pres
was | 1sg.past, 3sg.past
were | 1pl.past, 2sg.past, 2pl.past, 3pl.pastShow the common features for all word forms. Computed with the join-method (generalization, least upper bound).
>>> for form in occurrences:
... meanings = occurrences[form]
... common = fs.join(meanings)
... print('%4s | %s' % (form, common))
am | [+1 +sg -pst]
are | [-pst]
is | [+3 +sg -pst]
was | [-2 +sg +pst]
were | [+pst]Their necessary conditions.
Advanced usage
To customize the behavior of the feature sets, override the FeatureSet attribute of FeatureSystem with your subclass:
>>> class MyFeatures(features.FeatureSystem.FeatureSet):
... @property
... def features(self):
... return list(self.concept.intent)
>>> class MyFeatureSystem(features.FeatureSystem):
... FeatureSet = MyFeatures
>>> myfs = MyFeatureSystem('small')
>>> myfs('1 -pl')
MyFeatures('+1 -pl')
>>> myfs('1 -pl').features
['+1', '-2', '-pl']Further reading
See also
concepts – Formal Concept Analysis with Python
fileconfig – Config file sections as objects
graphviz – Simple Python interface for Graphviz
License
Features is distributed under the MIT license.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Hashes for features-0.5.2-py2.py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 189c868f8d98825d8e96283998a4a71876271615374bc80ec17ba051918df3e7 |
|
| MD5 | 1738ddda9df0aa4741ad1e36ab16a96a |
|
| BLAKE2b-256 | 8864d4c3456b1c6fd197a4aeab036ee0829e49448b2fccaadeee4fa06c8f2b0f |







