A tool for fair and reproducible crowdsourcing using Toloka

Project description
𝚊𝚋𝚞𝚕𝚊𝚏𝚒𝚊: A tool for fair and reproducible crowdsourcing
𝚊𝚋𝚞𝚕𝚊𝚏𝚒𝚊 is a tool for creating and deploying tasks on the the Toloka crowdsourcing platform.
The tool allows you to create crowdsourcing tasks using pre-defined task interfaces and configuring their settings using YAML files.
For a description of the tool and the motivation for its development, see this publication.
Please cite the following publication if you use the tool in your research.
Tuomo Hiippala, Helmiina Hotti, and Rosa Suviranta. 2022. Developing a tool for fair and reproducible use of paid crowdsourcing in the digital humanities. In Proceedings of the 6th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature, pages 7–12, Gyeongju, Republic of Korea. International Conference on Computational Linguistics.
For convenience, you can find the BibTeX entry below.
@inproceedings{hiippala-etal-2022-developing,
title = "Developing a tool for fair and reproducible use of paid crowdsourcing in the digital humanities",
author = "Hiippala, Tuomo and Hotti, Helmiina and Suviranta, Rosa",
booktitle = "Proceedings of the 6th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature",
month = oct,
year = "2022",
address = "Gyeongju, Republic of Korea",
publisher = "International Conference on Computational Linguistics",
url = "https://aclanthology.org/2022.latechclfl-1.2",
pages = "7--12",
abstract = "This system demonstration paper describes ongoing work on a tool for fair and reproducible use of paid crowdsourcing in the digital humanities. Paid crowdsourcing is widely used in natural language processing and computer vision, but has been rarely applied in the digital humanities due to ethical concerns. We discuss concerns associated with paid crowdsourcing and describe how we seek to mitigate them in designing the tool and crowdsourcing pipelines. We demonstrate how the tool may be used to create annotations for diagrams, a complex mode of expression whose description requires human input.",
}
Installation
You can install the tool from PyPI using the following command: pip install abulafia
Alternatively, you can clone this repository and install the tool locally. Move to the directory that contains the repository and type: pip install .
Key concepts
𝚊𝚋𝚞𝚕𝚊𝚏𝚒𝚊 defines three basic components for building crowdsourcing pipelines: tasks, actions and task sequences.
In Toloka terms, tasks are equal to projects, whereas task sequences consist of projects that are connected to each other. Actions, in turn, operate on the input/output data of projects.
Tasks
Each crowdsourcing task is specified and configured using a YAML file. Each configuration file should include the following keys:
nameof the task- the types of
inputandoutputdata under keydata actions, if applicableinterfacesettingsprojectsettingspoolsettings
Optionally, you can add quality_control settings. Options for quality control are the following:
- Fast responses
- Skipped assignments
- Re-do assignments from banned users
- Captcha
- Golden set (performance on control tasks)
See the directory examples/config for examples of YAML configuration files.
Blocklist: If you want to prevent some users from having access to a specific pool, add the key blocklist under pool configuration and give a path to a TSV file containing the column user_id with user identifiers of the workers you would like to block (see the example in examples/config/detect_text.yaml).
Actions
Just like crowdsourcing tasks, each action requires its own YAML configuration file. examples/action_demo.py defines a pipeline that uses the Aggregate, Forward and SeparateBBoxes actions.
Forward action requires the following keys:
nameof the actiondatasource, the pool where the tasks to be forwarded originate
Variable names for the possible outputs for the source task and pools to which they should be forwarded are configured under the key on_result under actions.
You can either configure a pool to which to forward, or use the keywords accept or reject to automatically accept or reject tasks based on the output. These keywords are meant to be used for tasks that involve workers verifying work submitte by other workers.
For example, you can ask workers to determine if an image has been annotated correctly. You can then use aggregation and forwarding to automatically accept or reject the original task by using key-value pairs such as correct: accept and incorrect: reject in your Forward configuration. You can also configure both accepting/rejecting and forwarding to another pool. In that case, use a list as the value for the variable name of the output. See the file examples/action_demo.py and the associated YAML configuration files for an example.
Configure Forward actions to the source pool/action under actions with the key on_result.
Aggregate action requires the keys:
nameof the actionsource, the pool from which tasks go to the aggregate action- The forward action to which the aggregated results will be sent should be configured under key
on_resultunderactions method, which is the desired aggregation algorithm. For now, categorical methods are supported.
Configure Aggregate actions to the source pool under actions with the key on_closed; aggregation can only be done after all tasks are complete and the pool is closed.
SeparateBBoxes action requires the keys:
nameof the action- The type of data that the action produces should be configured under the key
outputunderdata
If you wish to start your pipeline with SeparateBBoxes, configure it under actions as value for the key data_source in the following pool. Then, the action reads a TSV file with images and bounding boxes and separates the bounding boxes to one per task. Note that the bounding boxes must be in the format that Toloka uses. If you want to have the action in the middle of a pipeline, you can configure it in your Forward action under one of the possible outputs of your task (for example; if you want all tasks with the output True to be forwarded to SeparateBBoxes, configure True: name_of_your_separatebboxes_action under on_result under actions. See config/forward_verify.yaml for an example). If you want, you can add a label for the bounding boxes in the resulting tasks, by giving the label as a value for the parameter add_label. Labelled bounding boxes are used in, for example, AddOutlines and LabelledSegmentationVerification tasks.
Task sequences
Task sequences are pipelines can consist of crowdsourcing tasks as well as actions that perform operations before, between or after tasks. The Forward action is used to transfer tasks from one pool to another based on task output. The Aggregate action is used to aggregate the output of a task; the action uses your aggregation algorithm of choice to determine the most probable output to a task. SeparateBBoxes is an action that takes an image with several bounding boxes, separates the bounding boxes to one per image, and creates new tasks from those.
If you wish to move tasks from one pool to another based on the acceptance status of the task, not the task output, you can configure the receiving pool under actions with keys on_submitted, on_accepted or on_rejected. For example, if you wish rejected work to go back to the pool to be re-completed by another worker, you can configure the current pool as value to the key on_rejected.
To deploy your crowdsourcing tasks to Toloka, the tool needs to read your credentials from a JSON file e.g. creds.json. Remember to never add this file to public version control. The contents of the file should be the following:
{
"token": "YOUR_OAUTH_TOKEN",
"mode": "SANDBOX"
}
When you've tested your pipeline in the Toloka sandbox, change the value for "mode" from "SANDBOX" to "PRODUCTION".
See the directory examples/ for examples of crowdsourcing pipelines.
The screenshot below shows an example of running the tool.
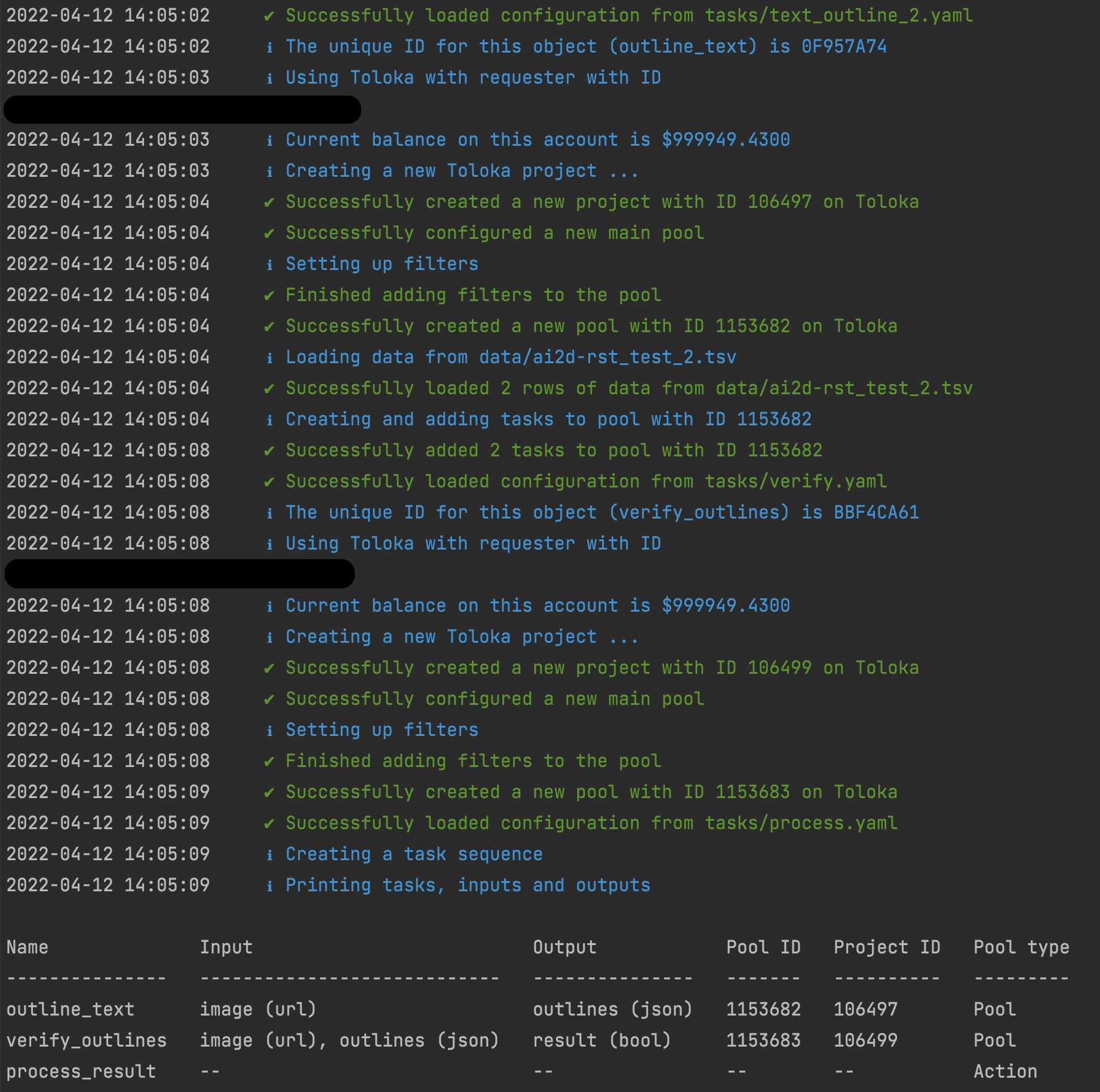
Ensuring fair payments
The tool has a built-in mechanism that guides the user to determine rewards that result in a fair hourly wage ($12) for the crowdsourced workers. In the pool configuration, the user should add a key estimated_time_per_suite. The value for the key should be the estimated time in seconds it takes for the worker to complete one task suite. Based on this value and the value reward_per_assignment, the tool checks if the reward is high enough to result in a fair hourly wage. The user is presented with a warning and prompted to cancel the pipeline if the configured reward is too low. A warning is also raised if estimated_time_per_suite is not found in the pool configuration.
To calculate a fair reward per task suite, you can use the interactive script utils/calculate_fair_rewards.py.
Pre-defined interfaces
Define crowdsourcing tasks in a Python file by creating one or many of the task objects listed below. They all take arguments configuration, which is the path to the correct YAML configuration file, and client, which should be your Toloka client.
You can define additional task interfaces by inheriting the CrowdsourcingTask class. The currently implemented task interfaces can be found in src/abulafia/task_specs/task_specs.py. These task interfaces are described in greater detail below.
ImageClassification
Interface for binary image classification tasks.
| input | output |
|---|---|
url (image) |
boolean (true/false) |
ImageSegmentation
Interface for image segmentation tasks.
| input | output |
|---|---|
url (image) |
json (bounding boxes) |
AddOutlines
Interface for image segmentation tasks with pre-existing labelled outlines.
| input | output |
|---|---|
url (image) |
json (bounding boxes) |
json (bounding boxes) |
SegmentationClassification
Interface for binary segmentation classification tasks.
| input | output |
|---|---|
url (image) |
boolean (true/false) |
json (bounding boxes) |
input: url to an image, JSON coordinates of bounding boxes
output: boolean
SegmentationVerification
Interface for binary segmentation verification tasks.
| input | output |
|---|---|
url (image) |
boolean (true/false) |
json (bounding boxes) |
LabelledSegmentationVerification
Interface for verifying image segmentation tasks where the bounding boxes have labels.
| input | output |
|---|---|
url (image) |
boolean (true/false) |
json (bounding boxes) |
FixImageSegmentation
Interface for fixing and adding more outlines to images with pre-existing non-labelled outlines.
| input | output |
|---|---|
url (image) |
json (bounding boxes) |
json (bounding boxes) |
MulticlassVerification
Interface for verification tasks with more than two possible outputs (for example: yes, no and maybe).
| input | output |
|---|---|
url (image) |
string (values) |
json (bounding boxes) |
TextClassification
Interface for the classification of text.
| input | output |
|---|---|
string |
string |
TextAnnotation
Interface for annotation words or other segments within a text.
| input | output |
|---|---|
string |
json |
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Hashes for abulafia-0.1.10-py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 8313bee03aa08a93edde0ddab9cdf98d776da3d074c3639e8b9d408b4033a8dd |
|
| MD5 | 5244d1a3d8f65c71d79f89273d7db8f2 |
|
| BLAKE2b-256 | dba5a961f7b366be6d31735c5b6942337c14377fe61cd3d0b88781548abf38ca |







