A spider for Dcard through its newest API.

Project description



Get posts and forums resourses through Dcard practical API on website.
Feature
Embrace asynchronous tasks and multithreads. All works done in parallel or coroutine-like. Spider needs for speed.
Installation
$ pip install dcard-spider
Dependencies
Python 2.6+, Python 3.3+
Example
from dcard import Dcard
def 先過濾出標題含有作品關鍵字(metas):
return [meta['id'] for meta in metas if '#作品' in meta['title']]
if __name__ == '__main__':
dcard = Dcard()
ids = dcard.forums('photography').get_metas(pages=3, callback=先過濾出標題含有作品關鍵字)
posts = dcard.posts(ids).get(comments=False, links=False)
resources = posts.parse_resources(constraints={'likeCount': '>=20'})
status = posts.download(resources)
print('成功下載!' if all(status) else '出了點錯下載不完全喔')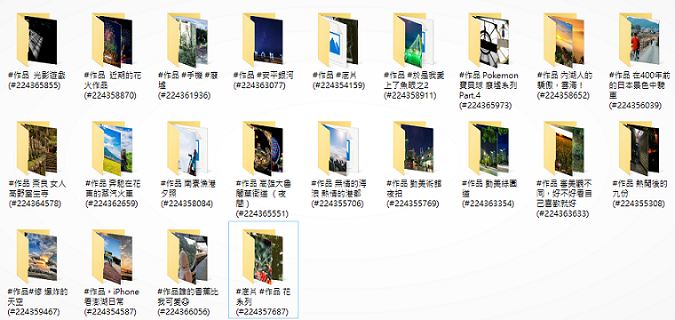
Usage
Basic
取得看板資訊 (metadata)
可用參數no_school調整是否取得學校看版內容。
forums = dcard.forums.get()
forums = dcard.forums.get(no_school=True)
print(len(forums))取得看板文章資訊 (metadata),一頁有30篇文章
可用 pages 指定頁數數量
文章排序有兩種選擇: new / popular
ariticle_metas = dcard.forums('funny').get_metas(pages=5, sort='new')
ariticle_metas = dcard.forums('funny').get_metas(pages=1, sort='popular')
print(len(ariticle_metas))提供一次取得 單篇/多篇 文章詳細資訊(全文、引用連結、所有留言)
# 放入 文章編號/單一meta資訊 => return 單篇文章
article = dcard.posts(224341009).get()
article = dcard.posts(ariticle_metas[0]).get()
# 放入 複數文章編號/多個meta資訊 => return 一串文章
ids = [meta['id'] for meta in ariticle_metas]
articles = dcard.posts(ids).get()
articles = dcard.posts(ariticle_metas).get()下載文章中的資源 (目前支援文中 imgur 連結的圖片)
可加入限制 (constraints) 過濾出符合條件的文章後,再進行分析
可以使用多個限制條件
預設每篇圖片儲存至 文章標題 (#文章編號) 為名的新資料夾
resources = posts.parse_resources(constraints={'likeCount': '>=100')
resources = posts.parse_resources(constraints={'likeCount': '>=20', 'commentCount': '>10'})
status = posts.download(resources)Advanced
提供自定義 callback function,可在接收回傳值前做處理 (filter / reduce data)。
def collect_ids(metas):
return [meta['id'] for meta in metas]
def 標題含有圖片關鍵字(metas):
return [meta['id'] for meta in metas if '#圖' in meta['title']]
ids = dcard.forums('funny').get_metas(pages=5, callback=collect_ids)
ids = dcard.forums('funny').get_metas(pages=5, callback=標題含有圖片關鍵字)
print(len(ids))爬取文章時提供 content, links, comments 三個參數,能選擇略過不需要的資訊以加快爬蟲速度。
posts = dcard.posts(ids).get(comments=False, links=False)
print(len(posts))Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
dcard-spider-0.2.0.zip
(15.6 kB
view hashes)







