Sentiment analysis library for russian language

Project description
Dostoevsky 


Sentiment analysis library for russian language
Install
Please note that Dostoevsky supports only Python 3.6+
$ pip install dostoevsky
Social networks comment model
This model was trained on RuSentiment dataset and achieves up to ~0.70 F1 score
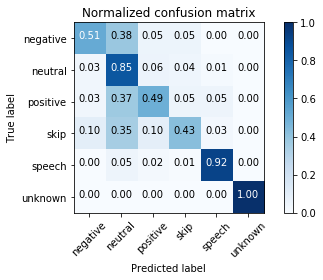
Usage
First of all, you'll need to download pretrained word embeddings and model:
$ dostoevsky download vk-embeddings cnn-social-network-model
Then, we can build our pipeline: text -> tokenizer -> word embeddings -> CNN
from dostoevsky.tokenization import UDBaselineTokenizer, RegexTokenizer
from dostoevsky.embeddings import SocialNetworkEmbeddings
from dostoevsky.models import SocialNetworkModel
tokenizer = UDBaselineTokenizer() or RegexTokenizer()
tokens = tokenizer.split('всё очень плохо') # [('всё', 'ADJ'), ('очень', 'ADV'), ('плохо', 'ADV')]
embeddings_container = SocialNetworkEmbeddings()
vectors = embeddings_container.get_word_vectors(tokens)
vectors.shape # (3, 300) - three words/vectors with dim=300
model = SocialNetworkModel(
tokenizer=tokenizer,
embeddings_container=embeddings_container,
lemmatize=False,
)
messages = [
'наступили на ногу',
'всё суперски',
]
results = model.predict(messages)
for message, sentiment in zip(messages, results):
print(message, '->', sentiment) # наступили на ногу -> negative
License

Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
dostoevsky-0.2.1.tar.gz
(8.0 kB
view hashes)
Built Distribution
Close
Hashes for dostoevsky-0.2.1-py2.py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 0417e7fa552b67a5dc988ef182e23eda446918fe333cd653bf39a6d6af24f6e5 |
|
| MD5 | 90c603b9e41dbea9a5becc44bc11c64b |
|
| BLAKE2b-256 | c81aaf50d8aa216bbefd5b3b617de7f336f3bcd3fbaa86f21836c6bdb07b64f9 |







