Adaptive Elastic Multi-Site Downloading

Project description
Adaptive, Elastic Multi-Server Downloading










Who would flardls bear?

Enabling Sustainable Downloading
Climate change makes consideration of efficiency and sustainability more important than ever in designing computations, especially if those computations may grow to be large. In computational science, downloads may consume only a tiny fraction of cycles but a noticeable fraction of the wall-clock time.
Unless we are on an exceptionally fast network, the download bit rate of our local LAN-WAN link is the limit that matters most to downloading time. Computer networking is packet-switched, with limits placed on the number of packets per unit of time by both hardware limitations and network policies. One can think of download times as given by that limiting bit transfer rate that are moderated by periods of waiting tp start transfers or acknowledge packets received. Synchronous downloads are highly energy-inefficient because a lot of energy-consuming hardware (CPU, memory, disk) is simply waiting for those starts and acknowledgements. It's far more sustainable to arrange the computational graph to do transfers simultaneously and asynchronously using multiple simultaneous connections to a server or connections to multiple servers or both, because that reduces wall-clock time spent waiting for initiation and acknowledgements.
Flardl downloads lists of files using an approach that adapts to local conditions and is elastic with respect to changes in network performance and server loads. Flardl achieves download rates typically more than 300X higher than synchronous utilities such as curl, while use of multiple servers provides superior robustness and protection against blacklisting. Download rates depend on network bandwidth, latencies, list length, file sizes, and HTTP protocol used, but even a single server on another continent can usually saturate a gigabit cable connection after about 50 files.
Queueing on Long Tails
Typically, one doesn't know much about the list of files to be downloaded, nor about the state of the servers one is going to use to download them. Once the first file request has been made to a given server, the algorithm has only two means of control. The first is how long to wait before waking up. The second is when the thread does wake up is whether to launch another download or wait some more. For collections of files that are highly predictable (for example, if all files are the same size) and all servers are equally fast, one simply divides the work equally. But real collections and real networks are rarely so well-behaved.
Collections of files generated by natural or human activity such as natural-language writing, protein structure determination, or genome sequencing tend to have size distributions with long tails. Such distributions have more big files than small files at a given size above or below the most-common (modal) size. Analytical forms of long-tail distributions include Zipf, power-law, and log-norm distributions. A real-world example of a long-tail distribution is shown below, which plots the file-size histogram for 1000 randomly-sampled CIF structure files from the Protein Data Bank, along with a kernel-density estimate and fits to log-normal and normal distributions.
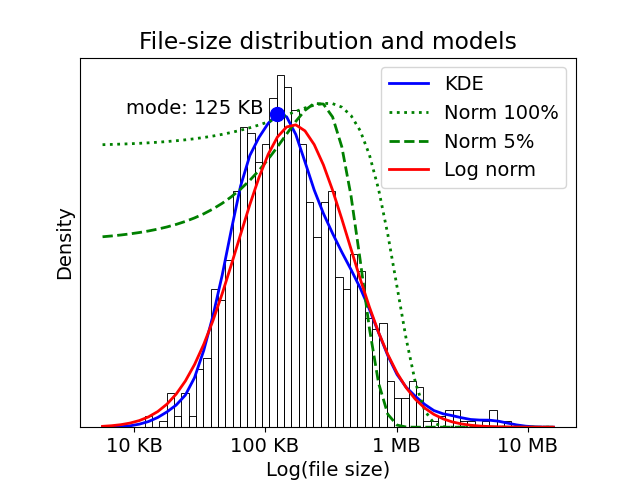
Queueing algorithms that rely upon per-file rates as the pricipal control mechanism implicitly assume that queue statistic can be approximated with a normal distribution. In making that assumption, they largely ignore the effects of big files on overall download statistics. Such software inevitably encounters big problems because mean values are neither stable nor characteristic of the distribution. As can be seen in the fits above, the mean and standard distribution of samples drawn from a long-tail distribution tend to grow with increasing sample size. In the example shown in the figure above, a fit of a normal distribution to a sample of 5% of the data (dashed line) gives a markedly-lower mean and standard deviation than the fit to all points (dotted line) and both fits are poor. The reason why the mean tend to grow larger with more files is because the more files sampled, the higher the likelihood that one of them will be huge. Algorithms that employ average per-file rates or times as the primary means of control will launch requests too slowly most of the time while letting queues run too deep when big downloads are encountered. While the mean per-file download time isn't a good statistic, the modal per-file download time $\tilde{t}_{\rm file}$ is better, at least on timescales over which network and server performance are consistent. You are not guaranteed to be the only user of either your WAN connection nor of the server, and sharing those resources impact download statistics in different ways, especially if multiple servers are involved.
Ignore the effects of finite packet size and treating the networking components shared among each connection as the main limitation to transfer rates, we can write the Equation of Time for the time required to receive file $i$ from server $j$ as approximately given by
$$ t_{i} = F_i - I_i \approx L_j + (c_{\rm ack} L_j + 1 /B_{\rm eff}) S_i + H_{ij}(i, D_j, D_{{\rm crit}_j}) $$
where
- $F_i$ is the finish time of the transfer,
- $I_i$ is the initial time of the transfer,
- $L_j$ is the server-dependent service latency, more-or-less the same as the value one gets from the ping command,
- $c_{\rm ack}$ is a value reflecting the number of service latencies required and the number of bytes transferred per acknowledgement, and while nearly constant given the HTTP and network protocols it is the part of the slope expression that is fit and not measured,
- $S_i$ is the size of file $i$,
- $B_{\rm lim}$ is the limiting download bit rate across all servers, which can be measured through network interface statistics if the transfer is long enough to reach saturation,
- $H_{ij}$ is the file- and server-dependent Head-Of-Line Latency that reflects waiting to get an active slot when the server queue depth $D_j$ is above some server-dependent critical value $D_{{\rm crit}_j}$.
If your downloading process is the only one accessing the server, the Head-Of-Line latency can be quantified via the relation
$$ H_{ij} = \array{ 0, & D_j < D_{{\rm crit}j} \cr I_i - F{i^{\prime}-D_j+D_{{\rm crit}j}-1}, & D_j \ge D{{\rm crit}_j} \cr } $$
where the prime in the subscript represents a re-indexing of entries in order of end times rather than start times. If other users are accessing the server at the same time, this expression becomes indeterminate, but with an expectation value of a multiple of the most-common file service time.
At queue depths small enough that no time is spent waiting to get to the head of the line, the file transfer time is linear in file size with the intercept given by the service latency and slope governed by an expression whose only unknown is a near-constant related to acknowledgements. As queue depth increases, transfer times are dominated by time spent waiting to get to the head of the queue.
Queue Depth is Toxic
At first glance, running at high queue depths seems attractive. One of the simplest queueing algorithm would to simply put every job in a queue at startup and let the server(s) handle requests in parallel and serial as best they can. But such non-adaptive non-elastic algorithms give poor real-world performance or multiple reasons. First, if there is more than one server queue, differing file sizes and tramsfer rates will result in the queueing equivalent of Amdahl's law, an "overhang" where one server still has many files queued up to serve while others have completed all requests.
Moreover, if a server decides you are abusing its queue policies, it may take action that hurts your current and future downloads. Most public-facing servers have policies to recognize and defend against Denial-Of-Service (DOS) attacks and a large number of requests from a single IP address in a short time is the main hallmark of a DOS attack. The minimal response to a DOS event causes the server to dump your latest requests, a minor nuisance. Worse is if the server responds by severely throttling further requests from your IP address for hours or sometime days. Worst of all, your IP address can get the "death penalty" and be put on a permanent blacklist that may require manual intervention for removal. Blacklisting might not even be your personal fault, but a collective problem. I have seen a practical class of 20 students brought to a complete halt by a server's 24-hour blacklisting of the institution's public IP address. Until methods are developed for servers to publish their "play-friendly" values and whitelist known-friendly servers, the highest priority for downloading algorithms must be to avoid blacklisting by a server by minimizing queue depth. However, the absolute minimum queue depth is retreating back to synchronous downloading. How can we balance the competing demands of speed and avoiding blacklisting?
A Fishing Metaphor
An analogy might help us here. Let's say you are a person who enjoys keeping track of statistics, and you decide to try fishing. At first, you have a single fishing rod and you go fishing at a series of local lakes where your catch consists of small bony fishes called "crappies". Your records reval that while the rate of catching fishes can vary from day to day--fish might be hungry or not--the average size of your catch is pretty stable. Bigger ponds tend to have bigger fish in them, and it might take slightly longer to reel in a bigger crappie than a small one, but big and small crappies average out pretty quickly.
One day you decide you love fishing so much, you drive to the coast and charter a fishing boat. On that boat, you can set out as many lines as you want (up to some limit) and fish in parallel. At first, you catch small bony fishes that are the ocean-going equivalent of crappies. But eventually you hook a small shark. Not does it take a lot of your time and attention to reel in a shark, but a landing a single shark totally skews the average weight of your catch. If you catch a small shark, then if you fish for long enough you will probably catch a big shark. Maybe you might even hook a small whale. But you and your crew can only effecively reel in so many hooked lines at once. Putting out more lines than that effective limit of hooked plus waiting-to-be-hooked lines only results in fishes waiting on the line, when they may break the line or get partly eaten before you can reel them in. Our theory of fishing says to put out lines at a high-side estimate of the most probable rate of catching fish until you reach the maximum number of lines the boat allows or until you catch enough fish to be able to estimate how the fish are biting. Then you back off the number of lines to the number that you and your crew can handle at a time that day.
Adaptilastic Queueing
Flardl implements a method I call "adaptilastic" queueing to deliver robust performance in real situations. Adaptilastic queueing uses timing on transfers from an initial period--launched using optimistic assumptions--to optimize later transfers by using the minimum total depth over all quese that will plateau the download bit rate while avoiding excess queue depth on any given server. Flardl distinguishes among four different operating regimes:
- Naive, where no transfers have ever been completed on a given server,
- Informed, where information from a previous run is available,
- Arriving, where information from at least one transfer to at least one server has occurred but not enough files have been transferred so that all statistics can be calculated,
- Updated, where a sufficient number of transfers has occurred to a server that file transfers may be fully characterized.
The optimistic rate at which flardl launches requests for a given server $j$ is given by the expectation rates for modal-sized files from the Equation of Time in the case of small queue depths where the Head-Of-Line term is zero as
$$ k_j = \array{ \tilde{S} B_{\rm max} / D_j, & \text{if naive}, \cr \tilde{\tau}{\rm prev} B{\rm max} / B_{\rm prev}, & \text{if informed}, \cr 1/(t_{\rm cur} - I_{\rm first}), & \text{if arriving,} \cr \tilde{\tau_j}, & \text{if updated,} \cr } $$
where
- $\tilde{S}$ is the modal file size for the collection,
- $B_{\rm max}$ is the maximum permitted download rate,
- $D_j$ is the server queue depth at launch,
- $\tilde{\tau}_{\rm prev}$ is the modal file arrival rate for the previous session,
- $B_{\rm prev}$ is the plateau download bit rate for the previous session,
- $t_{\rm cur}$ is the current time,
- $I_{\rm first}$ is the initiation time for the first transfer to arrive,
- and $\tilde{\tau_j}$ is the modal file transfer rate for the current session,
After waiting an exponentially-distributed stochastic period given by the applicable value for $k_j$, testing is done against three queue depth limits
- $D_{{\rm max}_j}$, the maximum per-server queue depth which is an input parameter (by default 100) that is updated if any queue requests are rejected.
- $D_{\rm sat}$, the total queue depth at which the download bit rate saturates or exceeds the maximum bit rate.
- $D_{{\rm crit}_j}$, the critical per-server queue depth. calculated each session when updated information
If any of the three queue depth limits is exceeded, a second stochastic wait period is added.
At low queue depths, one can fit to this expression to estimate the server latency $L_j$, the limiting download bit rate at saturation $B_{\rm lim}$, and the total queue depth at saturation $D_{\rm sat}$. If the server queue depth $D_j$ is run up high enough during the initial latency period before files are returned, one can estimate the critical queue depth $D_{{\rm crit}_j}$ by noting where the deviations approach a multiple of the modal transfer time. This estimate of critical queue depth reflects both server policy and overall server load at time of request.
As transfers are completed, flardl estimates the queue depth at which saturation was achieved (totalled over all servers), and updates its estimate of $B_{\rm eff}$ over all servers at saturation from the network interface statistics and the critical queue depth and modal per-file return rate on a per-server basis. These values form the bases for launching the remaining requests. The servers with higher modal service rates (i.e., rates of serving crappies) will spend less time waiting and thus stand a better chance at nabbing an open queue slot, without penalizing servers that happen to draw a big downloads (whales).
If File Sizes are Known
The adapilastic algorithm assumes that file sizes are randomly-ordered in the list. But what if we know the file sizes beforehand? The server that draws the biggest file is most likely to finish last, so it's important for that file to be started on the fastest server as soon as one has current information about which server is indeed fastest (i.e., by reaching the arriving state). One simple way of making downloads more optimal when file sizes are known is to sort the incoming list of download by size, downloading in order of ascending size until the server receives the first file, then switch to downloading in order of descending size.
Requirements
Flardl is tested under python 3.12, on Linux, MacOS, and Windows and under 3.9 thru 3.11 on Linux. Under the hood, flardl relies on httpx and is supported on whatever platforms that library works under, for both HTTP/1.1 and HTTP/2.
Installation
You can install Flardl via pip from PyPI:
$ pip install flardl
Usage
Flardl has no CLI and does no I/O other than downloading and writing files. See test examples for usage.
Contributing
Contributions are very welcome. To learn more, see the Contributor Guide.
License
Distributed under the terms of the BSD 3-clause license, flardl is free and open source software.
Issues
If you encounter any problems, please file an issue along with a detailed description.
Credits
Flardl was written by Joel Berendzen.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.







