A library that includes pure TF/Keras preprocessing and augmentation layers

Project description
KerasAug








Description
KerasAug is a library that includes pure TF/Keras preprocessing and augmentation layers, providing support for various data types such as images, labels, bounding boxes, segmentation masks, and more.


Note left: the visualization of the layers in KerasAug; right: the visualization of the YOLOV8 pipeline using KerasAug
KerasAug aims to provide fast, robust and user-friendly preprocessing and augmentation layers, facilitating seamless integration with TensorFlow, Keras and KerasCV.
KerasAug is:
- 🚀 faster than KerasCV which is an official Keras library
- 🧰 supporting various data types, including images, labels, bounding boxes, segmentation masks, and more.
- ❤️ dependent only on TensorFlow
- 🌟 seamlessly integrating with the
tf.dataandtf.keras.ModelAPIs - 🔥 compatible with GPU and mixed precision (
mixed_float16andmixed_bfloat16)
Check out the demo website powered by Streamlit:
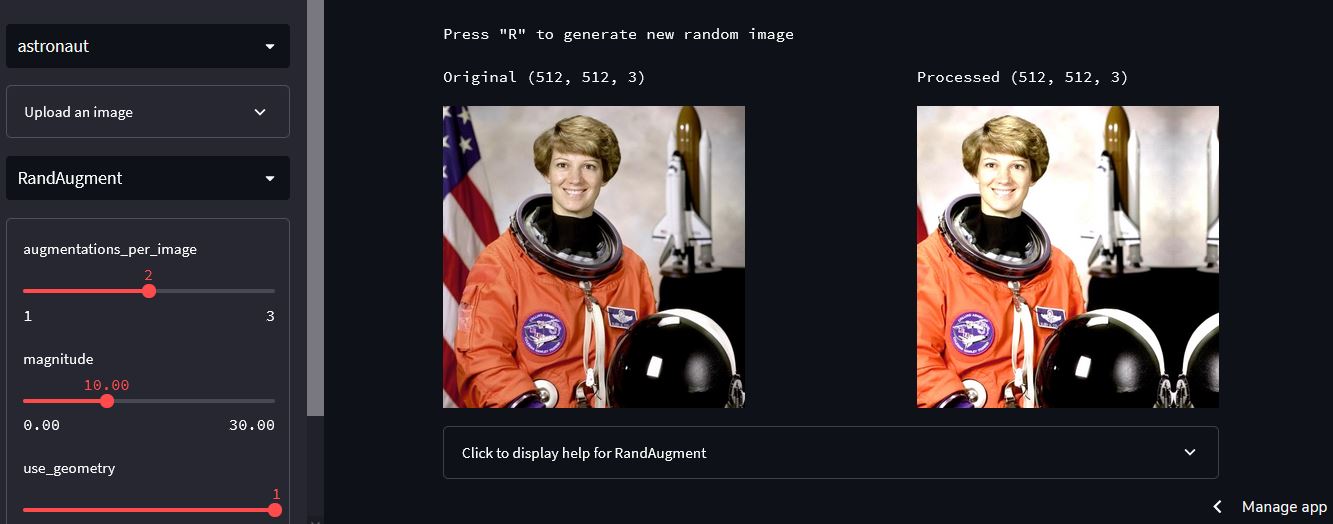
- Apply a transformation to the default or uploaded image
- Adjust the arguments of the specified layer
Why KerasAug?
-
KerasAug is generally faster than KerasCV
RandomCropAndResize in KerasAug exhibits a remarkable speed-up of +1150% compared to KerasAug. See keras-aug/benchmarks for more details.
-
The APIs of KerasAug are highly stable compared to KerasCV
KerasCV struggles to reproduce the YOLOV8 training pipeline, whereas KerasAug executes it flawlessly. See Quickstart for more details.
-
KerasAug comes with built-in support for mixed precision training
All layers in KerasAug can run with
tf.keras.mixed_precision.set_global_policy('mixed_float16') -
KerasAug offers the functionality of sanitizing bounding boxes, ensuring the validity
The current layers in KerasAug support the sanitizing process by incorporating the
bounding_box_min_area_ratioandbounding_box_max_aspect_ratioarguments.Note The degenerate bounding boxes (those located at the bottom of the image) are removed.

Installation
pip install keras-aug tensorflow --upgrade
Quickstart
Rock, Paper and Scissors Image Classification
import keras_aug
import keras_cv
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow import keras
# Create a preprocessing pipeline using KerasAug
BATCH_SIZE = 16
NUM_CLASSES = 3
augmenter = keras.Sequential(
[
keras_aug.layers.RandomFlip(),
keras_aug.layers.RandAugment(
value_range=(0, 255),
augmentations_per_image=3,
magnitude=15, # [0, 30]
magnitude_stddev=0.15,
),
keras_aug.layers.CutMix(),
]
)
def preprocess_data(images, labels, augment=False):
labels = tf.one_hot(labels, NUM_CLASSES)
inputs = {"images": images, "labels": labels}
outputs = augmenter(inputs) if augment else inputs
return outputs["images"], outputs["labels"]
train_dataset, test_dataset = tfds.load(
"rock_paper_scissors", as_supervised=True, split=["train", "test"]
)
train_dataset = (
train_dataset.batch(BATCH_SIZE)
.map(
lambda x, y: preprocess_data(x, y, augment=True),
num_parallel_calls=tf.data.AUTOTUNE,
)
.prefetch(tf.data.AUTOTUNE)
)
test_dataset = (
test_dataset.batch(BATCH_SIZE)
.map(preprocess_data, num_parallel_calls=tf.data.AUTOTUNE)
.prefetch(tf.data.AUTOTUNE)
)
# Create a model using a pretrained backbone
backbone = keras_cv.models.EfficientNetV2Backbone.from_preset(
"efficientnetv2_b0_imagenet"
)
model = keras_cv.models.ImageClassifier(
backbone=backbone,
num_classes=NUM_CLASSES,
activation="softmax",
)
model.compile(
loss="categorical_crossentropy",
optimizer=keras.optimizers.Adam(learning_rate=1e-5),
metrics=["accuracy"],
)
# Train your model
model.fit(
train_dataset,
validation_data=test_dataset,
epochs=8,
)
# KerasCV Quickstart
...
Epoch 8/8
158/158 [==============================] - 39s 242ms/step - loss: 0.7930 - accuracy: 0.7171 - val_loss: 0.2488 - val_accuracy: 0.9946
# KerasAug Quickstart
...
Epoch 8/8
158/158 [==============================] - 34s 215ms/step - loss: 0.7680 - accuracy: 0.7567 - val_loss: 0.2639 - val_accuracy: 1.0000
KerasAug runs faster (215ms/step vs. 242ms/step) than KerasCV and achieves better performance.
YOLOV8 Training Pipeline Demo
import keras_aug
import keras_cv
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow import keras
BATCH_SIZE = 16
OUTPUT_PATH = "output.png"
IMAGE_HEIGHT = 640
IMAGE_WIDTH = 640
FILL_VALUE = 114
def visualize_dataset(
inputs, value_range, rows, cols, bounding_box_format, path
):
inputs = next(iter(inputs.take(1)))
images, bounding_boxes = inputs["images"], inputs["bounding_boxes"]
keras_cv.visualization.plot_bounding_box_gallery(
images,
value_range=value_range,
rows=rows,
cols=cols,
y_true=bounding_boxes,
scale=5,
font_scale=0.7,
bounding_box_format=bounding_box_format,
path=path,
dpi=150,
)
def unpackage_raw_tfds_inputs(inputs, bounding_box_format):
image = inputs["image"]
boxes = keras_aug.datapoints.bounding_box.convert_format(
inputs["objects"]["bbox"],
images=image,
source="rel_yxyx",
target=bounding_box_format,
)
bounding_boxes = {
"classes": tf.cast(inputs["objects"]["label"], dtype=tf.float32),
"boxes": tf.cast(boxes, dtype=tf.float32),
}
return {
"images": tf.cast(image, tf.float32),
"bounding_boxes": bounding_boxes,
}
def load_pascal_voc(split, dataset, bounding_box_format):
ds = tfds.load(dataset, split=split, with_info=False, shuffle_files=False)
ds = ds.map(
lambda x: unpackage_raw_tfds_inputs(
x, bounding_box_format=bounding_box_format
),
num_parallel_calls=tf.data.AUTOTUNE,
)
return ds
augmenter = keras.Sequential(
layers=[
keras_aug.layers.Resize(
IMAGE_HEIGHT,
IMAGE_WIDTH,
pad_to_aspect_ratio=True,
padding_value=FILL_VALUE,
bounding_box_format="xywh",
),
keras_aug.layers.Mosaic(
IMAGE_HEIGHT * 2,
IMAGE_WIDTH * 2,
fill_value=FILL_VALUE,
bounding_box_format="xywh",
),
keras_aug.layers.RandomAffine(
translation_height_factor=0.1,
translation_width_factor=0.1,
zoom_height_factor=0.5,
same_zoom_factor=True,
fill_value=FILL_VALUE,
bounding_box_format="xywh",
bounding_box_min_area_ratio=0.1,
bounding_box_max_aspect_ratio=100.0,
),
keras_aug.layers.Resize(
IMAGE_HEIGHT, IMAGE_WIDTH, bounding_box_format="xywh"
),
# TODO: Blur, MedianBlur
keras_aug.layers.RandomApply(keras_aug.layers.Grayscale(), rate=0.01),
keras_aug.layers.RandomApply(
keras_aug.layers.RandomCLAHE(value_range=(0, 255)), rate=0.01
),
keras_aug.layers.RandomHSV(
value_range=(0, 255),
hue_factor=0.015,
saturation_factor=0.7,
value_factor=0.4,
),
keras_aug.layers.RandomFlip(bounding_box_format="xywh"),
]
)
train_ds = load_pascal_voc(
split="train", dataset="voc/2007", bounding_box_format="xywh"
)
train_ds = train_ds.ragged_batch(BATCH_SIZE, drop_remainder=True)
train_ds = train_ds.map(augmenter, num_parallel_calls=tf.data.AUTOTUNE)
visualize_dataset(
train_ds,
bounding_box_format="xywh",
value_range=(0, 255),
rows=2,
cols=2,
path=OUTPUT_PATH,
)
Benchmark
KerasAug is generally faster than KerasCV.
| Type | Layer | KerasAug | KerasCV | |
|---|---|---|---|---|
| Geometry | RandomHFlip | 2123 | 1956 | fair |
| RandomVFlip | 1871 | 1767 | fair | |
| RandomRotate | 1703 | 1723 | fair | |
| RandomAffine | 2578 | 2355 | fair | |
| RandomCropAndResize | 2664 | 213 | +1150% | |
| Resize (224, 224) | 2480 | 222 | +1017% | |
| Intensity | RandomBrightness | 3052 | 2768 | fair |
| RandomContrast* | 3099 | 2976 | fair | |
| RandomBrightnessContrast* | 2881 | 609 | +373% | |
| RandomColorJitter* | 2013 | 597 | +237% | |
| RandomGaussianBlur | 2345 | 203 | +1055% | |
| Invert | 2691 | X | ||
| Grayscale | 2917 | 3116 | fair | |
| Equalize | 196 | 139 | +41% | |
| AutoContrast | 3095 | 3025 | fair | |
| Posterize | 3033 | 2144 | fair | |
| Solarize | 3133 | 2972 | fair | |
| Sharpness | 2982 | 2833 | fair | |
| Regularization | RandomCutout | 2994 | 2795 | fair |
| RandomGridMask | 918 | 196 | +368% | |
| Mix | CutMix | 2967 | 2957 | fair |
| MixUp | 1897 | 1861 | fair | |
| Auto | AugMix | 79 | X (Error) | |
| RandAugment | 301 | 246 | +22% |
Note FPS (frames per second)
Please refer to benchmarks/README.md for more details.
Citing KerasAug
@misc{wood2022kerascv,
title={KerasCV},
author={Wood, Luke and Tan, Zhenyu and Stenbit, Ian and Bischof, Jonathan and Zhu, Scott and Chollet, Fran\c{c}ois and others},
year={2022},
howpublished={\url{https://github.com/keras-team/keras-cv}},
}
@misc{chiu2023kerasaug,
title={KerasAug},
author={Hongyu, Chiu},
year={2023},
howpublished={\url{https://github.com/james77777778/keras-aug}},
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Hashes for keras_aug-0.5.8-py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 50d7e618347da3686f23766c037856ea7c8c981dcaa3f028d3d5ab48690fdeec |
|
| MD5 | 76f9aadb3f74d1366cde512012836e95 |
|
| BLAKE2b-256 | c126282ddb1a459325a9f1ef9bbfdab65ca26aae9c7e61c2642b71931fe7367f |







