Lazy dict with universally unique identifier for values

Project description


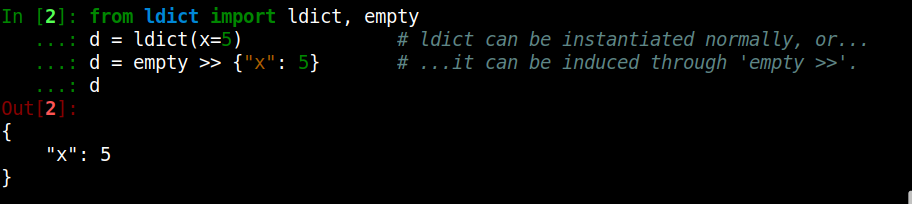
ldict
Uniquely identified lazy dict.
Overview
We consider that every value or data object is generated by a process, starting from empty.
The process is a sequence of transformation steps that can be of two types:
value insertion and function application.
Value insertion is done using dict-like objects as shown below.
The operator >> concatenate the steps chronologically.
Each value and each function have unique deterministic identifiers.
Identifiers for future values are predictable through the magic available here.
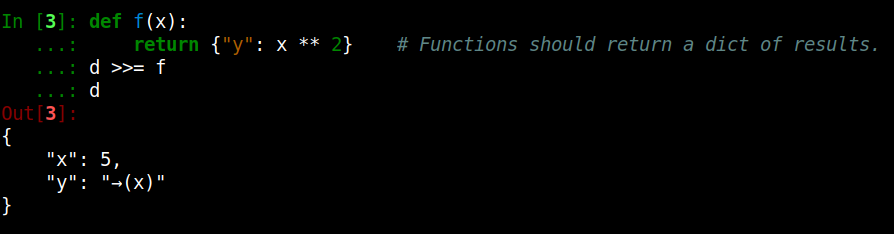
Function application is done in the same way.
The parameter names define the input fields,
while the keys in the returned dict define the output fields:
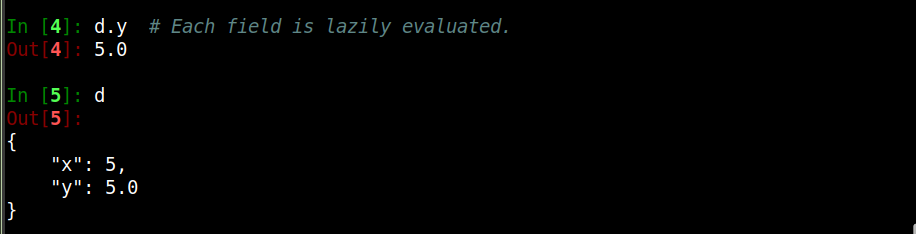
Similarly, for anonymous functions:

Finally, the result is only evaluated at request:

Installation
...as a standalone lib
# Set up a virtualenv.
python3 -m venv venv
source venv/bin/activate
# Install from PyPI...
pip install --upgrade pip
pip install -U ldict
# ...or, install from updated source code.
pip install git+https://github.com/davips/ldict
...from source
git clone https://github.com/davips/ldict
cd ldict
poetry install
Examples
Merging two ldicts
from ldict import ldict
a = ldict(x=3)
print(a)
"""
{
"id": "kr_4aee5c3bcac2c478be9901d57fd1ef8a9d002",
"ids": "kr_4aee5c3bcac2c478be9901d57fd1ef8a9d002",
"x": 3
}
"""
b = ldict(y=5)
print(b)
"""
{
"id": "Uz_0af6d78f77734fad67e6de7cdba3ea368aae4",
"ids": "Uz_0af6d78f77734fad67e6de7cdba3ea368aae4",
"y": 5
}
"""
print(a >> b)
"""
{
"id": "c._2b0434ca422114262680df425b85cac028be6",
"ids": "kr_4aee5c3bcac2c478be9901d57fd1ef8a9d002 Uz_0af6d78f77734fad67e6de7cdba3ea368aae4",
"x": 3,
"y": 5
}
"""
Lazily applying functions to ldict
from ldict import ldict
a = ldict(x=3)
print(a)
"""
{
"id": "kr_4aee5c3bcac2c478be9901d57fd1ef8a9d002",
"ids": "kr_4aee5c3bcac2c478be9901d57fd1ef8a9d002",
"x": 3
}
"""
a = a >> ldict(y=5) >> {"z": 7} >> (lambda x, y, z: {"r": x ** y // z})
print(a)
"""
{
"id": "8jopGVdtSEyCk1NSKcrEF-Lfv8up9MQBdvkLxU2o",
"ids": "J3tsy4vUXPELySBicaAy-h-UK7Dp9MQBdvkLxU2o... +2 ...Ss_7dff0a161ba7462725cac7dcee71b67669f69",
"r": "→(x y z)",
"x": 3,
"y": 5,
"z": 7
}
"""
print(a.r)
"""
34
"""
print(a)
"""
{
"id": "8jopGVdtSEyCk1NSKcrEF-Lfv8up9MQBdvkLxU2o",
"ids": "J3tsy4vUXPELySBicaAy-h-UK7Dp9MQBdvkLxU2o... +2 ...Ss_7dff0a161ba7462725cac7dcee71b67669f69",
"r": 34,
"x": 3,
"y": 5,
"z": 7
}
"""
Parameterized functions and sampling
from random import Random
from ldict import ø
from ldict.cfg import cfg
# A function provide input fields and, optionally, parameters.
# 'a' is sampled from an arithmetic progression
# 'b' is sampled from a geometric progression
# Here, the syntax for default parameter values is borrowed with a new meaning.
def fun(x, y, a=[-100, -99, -98, ..., 100], b=[0.0001, 0.001, 0.01, ..., 100000000]):
return {"z": a * x + b * y}
# Creating an empty ldict. Alternatively: d = ldict().
d = ø >> {}
d.show(colored=False)
"""
{
"id": "0000000000000000000000000000000000000000",
"ids": {}
}
"""
# Putting some values. Alternatively: d = ldict(x=5, y=7).
d["x"] = 5
d["y"] = 7
d.show(colored=False)
"""
{
"id": "I0_39c94b4dfbc7a8579ca1304eba25917204a5e",
"ids": {
"x": "Tz_d158c49297834fad67e6de7cdba3ea368aae4",
"y": "Rs_92162dea64a7462725cac7dcee71b67669f69"
},
"x": 5,
"y": 7
}
"""
# Parameter values are uniformly sampled.
d1 = d >> fun
d.show(colored=False)
"""
{
"id": "I0_39c94b4dfbc7a8579ca1304eba25917204a5e",
"ids": {
"x": "Tz_d158c49297834fad67e6de7cdba3ea368aae4",
"y": "Rs_92162dea64a7462725cac7dcee71b67669f69"
},
"x": 5,
"y": 7
}
"""
print(d1.z)
"""
69610.0
"""
d2 = d >> fun
d.show(colored=False)
"""
{
"id": "I0_39c94b4dfbc7a8579ca1304eba25917204a5e",
"ids": {
"x": "Tz_d158c49297834fad67e6de7cdba3ea368aae4",
"y": "Rs_92162dea64a7462725cac7dcee71b67669f69"
},
"x": 5,
"y": 7
}
"""
print(d2.z)
"""
-29.93
"""
# Parameter values can also be manually set.
e = d >> cfg(a=5, b=10) >> fun
print(e.z)
"""
95
"""
# Not all parameters need to be set.
e = d >> cfg(a=5) >> fun
print(e.z)
"""
70025.0
"""
# Each run will be a different sample for the missing parameters.
e = e >> cfg(a=5) >> fun
print(e.z)
"""
95.0
"""
# The metaparameter 'rnd' defines the initial state of the random sampler for this point onwards processing the ldict.
e = d >> cfg(a=5)(rnd=0) >> fun
print(e.z)
"""
725.0
"""
# All runs will yield the same result, if starting from the same random number generator seed.
e = e >> cfg(a=5)(rnd=0) >> fun
print(e.z)
"""
725.0
"""
# Reproducible different runs are achievable by passing a stateful random number generator, instead of a seed.
rnd = Random(0)
e = d >> cfg(a=5)(rnd=rnd) >> fun
print(e.z)
"""
725.0
"""
e = d >> cfg(a=5)(rnd=rnd) >> fun
print(e.z)
"""
700000025.0
"""
Composition of sets of functions
from random import Random
from ldict import ø
# A multistep process can be defined without applying its functions
from ldict.cfg import cfg
def g(x, y, a=[1, 2, 3, ..., 10], b=[0.00001, 0.0001, 0.001, ..., 100000]):
return {"z": a * x + b * y}
def h(z, c=[1, 2, 3]):
return {"z": c * z}
# In the ldict framework 'data is function',
# so the alias ø represents the 'empty data object' and the 'reflexive function' at the same time.
# In other words: 'inserting nothing' has the same effect as 'doing nothing'.
fun = ø * g * h # ø enable the cartesian product of the subsequent sets of functions within the expression.
print(fun)
"""
g×h
"""
# The difference between 'ø * g * h' and 'ldict(x=3) >> g >> h' is that the functions in the latter are already applied
# (resulting in an ldict object). The former still has its free parameters unsampled,
# and results in an ordered set of composite functions.
# It is a set because the parameter values of the functions are still undefined.
d = {"x": 5, "y": 7} >> fun
print(d)
"""
{
"id": "VNqIlnelOh9VJbgIBTtsB20MjhrHDycdeBrDsE9V",
"ids": "LzRJyJ7ApyJLoJ.OVI8m.1sp56rHDycdeBrDsE9V... +1 ...Rs_92162dea64a7462725cac7dcee71b67669f69",
"z": "→(z→(x y a b) c)",
"x": 5,
"y": 7
}
"""
print(d.z)
"""
2100090.0
"""
d = {"x": 5, "y": 7} >> fun
print(d.z)
"""
94.0
"""
# Reproducible different runs by passing a stateful random number generator.
rnd = Random(0)
e = d >> cfg()(rnd=rnd) >> fun
print(e.z)
"""
105.0
"""
e = d >> cfg()(rnd=rnd) >> fun
print(e.z)
"""
14050.0
"""
rnd = Random(0)
e = d >> cfg()(rnd=rnd) >> fun
print(e.z)
"""
105.0
"""
e = d >> cfg()(rnd=rnd) >> fun
print(e.z)
"""
14050.0
"""
Concept
A ldict is like a common Python dict, with extra funtionality and lazy.
It is a mapping between string keys, called fields, and any serializable object.
The ldict id (identifier) and the field ids are also part of the mapping.
The user can provide a unique identifier (hosh) for each function or value object. Otherwise, they will be calculated through blake3 hashing of the content of data or bytecode of function. For this reason, such functions should be simple, i.e., with minimal external dependencies, to avoid the unfortunate situation where two functions with identical local code actually perform different calculations through calls to external code that implement different algorithms with the same name.
Grants
This work was partially supported by Fapesp under supervision of Prof. André C. P. L. F. de Carvalho at CEPID-CeMEAI (Grants 2013/07375-0 – 2019/01735-0).
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Hashes for ldict-2.210908.7-py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 7e33d8844482d136b0d1718092f4f330bb8fd265f6e10136cdc89e0d87749e3b |
|
| MD5 | 2b0c9f4ff64b43bcbd2a0b350e430651 |
|
| BLAKE2b-256 | 6067b8eb2f3a13b8e0b4d6114c67561289edb4ed284dca47abe48ee7832818b1 |







