Model Error Analysis python package

Project description

Introduction
mealy is a Python package to perform Model Error AnaLYsis of scikit-learn models leveraging an Error Tree.
The project is currently maintained by Dataiku's research team.
This is an alpha version.
Getting started
MEA documentation features some examples helping you getting started with Model Error Analysis:
- Error Analysis on scikit-learn model presents a basic error analysis on a regression model for structured data.
- Error Analysis on pipeline model presents a basic error analysis on a classification pipeline for structured data.
Model Error Analysis
After training a ML model, data scientists need to investigate the model failures to build intuition on the critical sub-populations on which the model is performing poorly. This analysis is essential in the iterative process of model design and feature engineering and is usually performed manually.
The mealy package streamlines the analysis of the samples mostly contributing to model errors and provides the user with automatic tools to break down the model errors into meaningful groups, easier to analyze, and to highlight the most frequent type of errors, as well as the problematic features correlated with the failures.
We call the model under investigation the primary model.
This approach relies on an Error Tree, a secondary model trained to predict whether the primary model prediction is correct or wrong, i.e. a success or a failure. More precisely, the Error Tree is a binary DecisionTree classifier predicting whether the primary model will yield a Correct Prediction or a Wrong Prediction.
The Error Tree can be trained on any dataset meant to evaluate the primary model performances, thus containing ground truth labels. In particular the provided primary test set is split into a secondary training set to train the Error Tree and a secondary test set to compute the Error Tree metrics.
In classification tasks the model failure is a wrong predicted class, whereas in case of regression tasks the failure is defined as a large deviation of the predicted value from the true one. In the latter case, when the absolute difference between the predicted and the true value is higher than a threshold ε, the model outcome is considered as a Wrong Prediction. The threshold ε is computed as the knee point of the Regression Error Characteristic (REC) curve, ensuring the absolute error of primary predictions to be within tolerable limits.
The leaves of the Error Tree decision tree break down the test dataset into smaller segments with similar features and similar model performances. Analyzing the sub-population in the error leaves, and comparing with the global population, provides insights about critical features correlated with the model failures.
The mealy package leads the user to focus on what are the problematic features and what are the typical values of these features for the mis-predicted samples. This information can later be exploited to support the strategy selected by the user :
- improve model design: removing a problematic feature, removing samples likely to be mislabeled, ensemble with a model trained on a problematic subpopulation, ...
- enhance data collection: gather more data regarding the most erroneous under-represented populations,
- select critical samples for manual inspection thanks to the Error Tree and avoid primary predictions on them, generating model assertions.
The typical workflow in the iterative model design supported by error analysis is illustrated in the figure below.
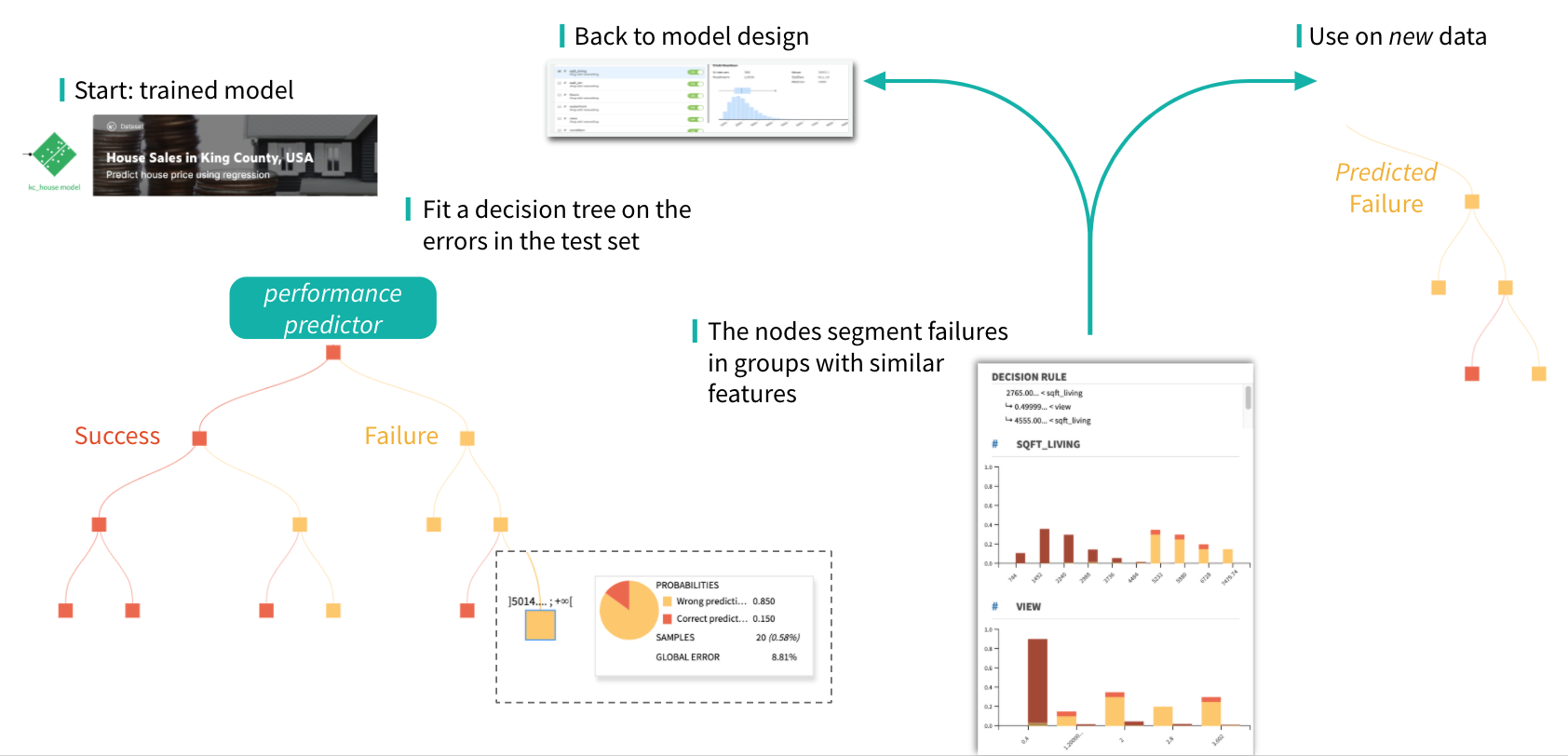
Getting started with mealy
Let (X_train, y_train) be the training data of the model to analyze, and (X_test, y_test) its test set.
The Model Error Analysis can be performed as:
from mealy.error_analyzer import ErrorAnalyzer
from mealy.error_visualizer import ErrorVisualizer
# train any scikit-learn model
model = RandomForestClassifier(n_estimators=10)
model.fit(X_train, y_train)
# fit an Error Tree on the model performances
error_analyzer = ErrorAnalyzer(model, feature_names=feature_names)
error_analyzer.fit(X_test, y_test)
# print metrics regarding the Error Tree
print(error_analyzer.evaluate(X_test, y_test))
# plot the Error Tree
error_visualizer = ErrorVisualizer(error_analyzer)
error_visualizer.plot_error_tree()
# return the details on the decision tree "error leaves" (leaves that contain a majority of errors)
error_analyzer.get_error_leaf_summary(leaf_selector=None, add_path_to_leaves=True);
# plot the feature distributions of samples in the "error leaves"
# features are ranked by their correlation to error
error_visualizer.plot_feature_distributions_on_leaves(leaf_selector=None, top_k_features=3)
Using mealy with pipeline to undo feature pre-processing
Let (X_train, y_train) be the training data of the model to analyze, and (X_test, y_test) its test set.
The numeric features numerical_feature_names are for instance pre-processed by a simple imputer and standard scaler,
while the categorical features categorical_feature_names are one-hot encoded.
The full pre-processing is provided to a Pipeline object in the form of a scikit-learn column transformer.
The last step of the pipeline is the model to analyze.
Among the transfomers available in sklearn.preprocessing
KBinDiscretizer and PolynomialFeatures are currently not supported.
The Model Error Analysis can be performed as:
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import make_column_transformer
from sklearn.pipeline import make_pipeline
from sklearn.impute import SimpleImputer
from mealy.error_analyzer import ErrorAnalyzer
from mealy.error_visualizer import ErrorVisualizer
transformers = [
(make_pipeline(SimpleImputer(), StandardScaler()), numerical_feature_names),
(OneHotEncoder(handle_unknown='ignore'), categorical_feature_names)
]
preprocess = make_column_transformer(
*transformers
)
pipeline_model = make_pipeline(
preprocess,
RandomForestClassifier(n_estimators=10))
# train a pipeline model
pipeline_model.fit(X_train, y_train)
# fit an Error Tree on the model performances
error_analyzer = ErrorAnalyzer(pipeline_model, feature_names=feature_names)
error_analyzer.fit(X_test, y_test)
# print metrics regarding the Error Tree
print(error_analyzer.evaluate(X_test, y_test))
# plot the Error Tree
error_visualizer = ErrorVisualizer(error_analyzer)
error_visualizer.plot_error_tree()
# return the details regarding the decision tree "error leaves" (leaves that contain a majority of errors)
error_analyzer.get_error_leaf_summary(leaf_selector=None, add_path_to_leaves=True);
# plot the feature distributions of samples in the "error leaves"
# features are ranked by their correlation to error
error_visualizer.plot_feature_distributions_on_leaves(leaf_selector=None, top_k_features=3)
Installation
Dependencies
mealy depends on:
- Python >= 3.5
- NumPy >= 1.11
- SciPy >= 0.19
- scikit-learn >= 0.19
- matplotlib >= 2.0
- graphviz >= 0.14
- kneed == 0.6
Installing with pip
The easiest way to install mealy is to use pip. For a vanilla install, simply type:
pip install -U mealy
Contributing
Contributions are welcome. Check out our contributing guidelines.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.







