Motiflets - Simple and Accurate Detection of Motifs in Time Series

Project description
Motiflets
This page was built in support of our paper "Motiflets - Simple and Accurate Detection of Motifs in Time Series" by Patrick Schäfer and Ulf Leser, published at PVLDB, 16(4): 725 - 737, 2022.
Supporting Material
notebooks: Please see the Jupyter Notebooks for use casescsvs: The results of the scalability experimentsmotiflets: Code implementing k-Motifletdatasets: Use cases in the paperjars: Java code of the competitors used in out paper: EMMA, Latent Motifs and Set Finder.
k-Motiflets
Intuitively speaking, k-Motiflets are the set of the exactly k most similar subsequences.
$k$-Motiflets are a novel definition for MD that turns the problem upside-down. $k$-Motiflets take the desired motif set size $k$ as parameter and maximize the similarity of the motif set. This $k$ is an integer with an easily understood interpretation, and in many use cases the expected size of the motif set is known prior to the analysis. Consider for example the possible copyright fraud in the pop song Ice “Ice Baby” by Vanilla Ice compared to “Under pressure” by Queen / David Bowie. Listening to these songs it is easy to obtain an initial guess of the number of repetitions (parameter $k$) of the problematic sections. On the other hand, it is impossible for humans to guess a good value for the numerical, real-valued distance between the different repetitions (parameter r).
We argue that guessing k is almost always easier, as the concept of how many repetitions of a motif do you expect is easy to understand - though the guess itself need not be easy and thus we will also offer algorithms to learn $k$. Furthermore, as $k$ is an integer, there is only a very limited number of options, as use cases with thousands of motif occurrences are rare. In contrast, the concept of how far apart do you expect motifs to be at maximum is extremely difficult to understand as distances (far apart) are measured by an opaque mathematical formula for which no intuition exists. Furthermore, $r$ is a real value with infinitely many values, and even small changes may lead to gross changes in the motif found.
Showcase
The following video highlights the ease of use of $k$-Motiflets using an ECG recording from the Long Term Atrial Fibrillation (LTAF) database.
In essence, there is no need for tuning any real-valued similarity threshold via trial-and-error, as is the case for virtually all motif set competitors. Instead, for $k$-Motiflets we may either directly set the maximal number of repetitions $k$ of a motif, or simply learn this value from the data.
https://user-images.githubusercontent.com/7783034/173186103-c8b6302e-2434-4a09-89f4-ddad2e63f997.mp4
Installation
The easiest is to use pip to install motiflets.
a) Install using pip
pip install motiflets
You can also install the project from source.
b) Build from Source
First, download the repository.
git clone https://github.com/patrickzib/motiflets.git
Change into the directory and build the package from source.
pip install .
Usage
Here we illustrate how to use k-Motiflets.
The following TS is an ECG from the Long Term Atrial Fibrillation (LTAF) database, which is often used for demonstrations in motif discovery (MD). The problem is particularly difficult for MD as actually two motifs exists: The first half of the TS contains a rectangular calibration signal with 6 occurrences, and the second half shows ECG heartbeats with 16 to 17 occurrences.

The major challenges in motif discovery are to learn the length of interesting motifs and to find the largest set of the same motif, i.e. all repetitions.
Learning the motif length l
We first extract meaningful motif lengths (l) from this use case:
# The Motiflets-class
ml = Motiflets(
ds_name, # the name of the series
series, # the data
df_gt, # ground truth, if available
n_jobs # number of jobs (cores) to be used.
)
k_max = 20
length_range = np.arange(25,200,25)
motif_length = ml.fit_motif_length(k_max, length_range)
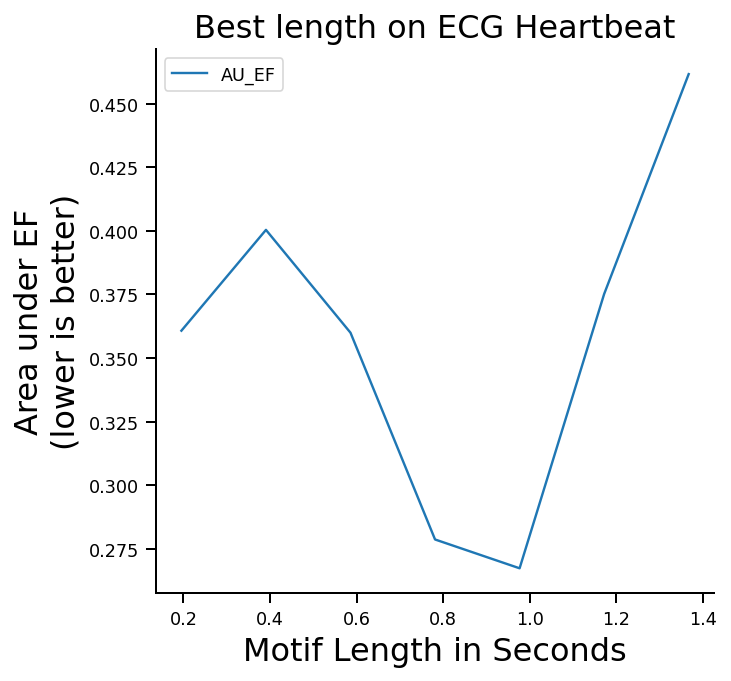
The plot shows that meaningful motifs are within a range of 0.8s to 1s, equal to roughly a heartbeat rate of 60-80 bpm.
Learning the motif size k
To extract meaningful motif sizes (k) from this use case, we run
dists, candidates, elbow_points = ml.fit_k_elbow(
k_max,
motif_length
)
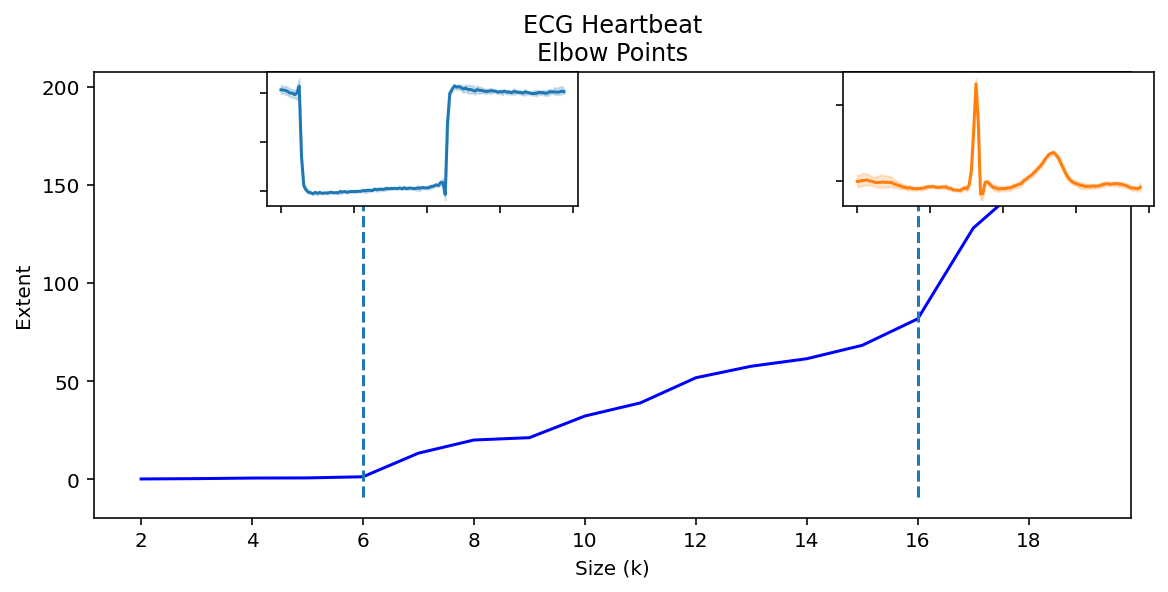
The variable elbow_points holds characteristic motif sizes found.
Elbow points represent meaningful motif sizes. Here, $6$ and $16$ are elbows, which are
the 6 calibration waves and the 16 heartbeats.
We finally plot these motifs:
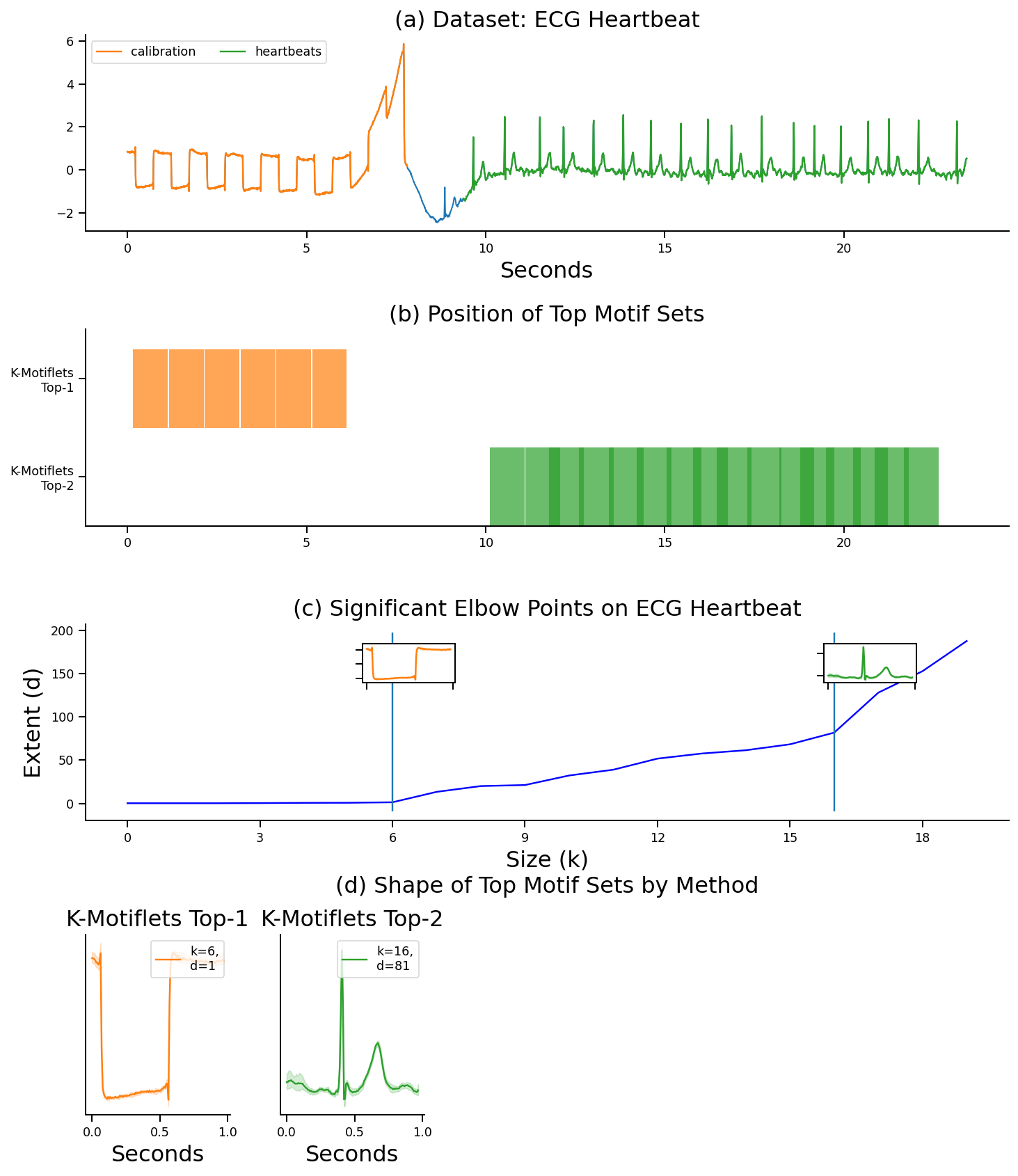
The first repetitions perfectly match the calibration signal (orange), while the latter 16 repetitions perfectly match the ECG waves (green).
Use Cases
Data Sets: We collected challenging real-life data sets to assess the quality and scalability of MD algorithms. An overview of datasets can be found in Table 2 of our paper.
-
Jupyter-Notebook Use Cases for k-Motiflets: highlights all use cases used in the paper and shows the unique ability of k-Motiflets to learn its parameters from the data and find itneresting motif sets.
-
Jupyter-Notebook Vanilla Ice - Ice Ice Baby: This time series is a TS extracted from the pop song Ice Ice Baby by Vanilla Ice using the 2nd MFCC channel sampled at 100Hz. This TS is particularly famous pop song, as it is alleged to have copied its riff from "Under Pressure" by Queen and David Bowie. It contains 20 repeats of the riff in 5 blocks with each riff being 3.6−4s long.
-
Jupyter-Notebook Muscle Activation was collected from professional in-line speed skating on a large motor driven treadmill with Electromyo- graphy (EMG) data of multiple movements. It consists of 29.899 measurements at 100Hz corresponding to 30s in total. The known motifs are the muscle movement and a recovery phase.
-
Jupyter-Notebook ECG Heartbeats contains a patient’s (with ID 71) heartbeat from the LTAF database. It consists of 3.000 measurements at 128𝐻𝑧 corresponding to 23𝑠. The heartbeat rate is around 60 to 80 bpm. There are two motifs: A calibration signal and the actual heartbeats.
-
Jupyter-Notebook Physiodata - EEG sleep data contains a recording of an after- noon nap of a healthy, nonsmoking person, between 20 to 40 years old [10]. Data was recorded with an extrathoracic strain belt. The dataset consists of 269.286 points at 100H𝑧 corresponding to 45𝑚𝑖𝑛. Known motifs are so-called sleep spindles and 𝑘-complexes.
-
Jupyter-Notebook Industrial Winding Process is a snapshot of a process where a plastic web is unwound from a first reel (unwinding reel), goes over the second traction reel and is finally rewound on the the third rewinding reel. The recordings correspond to the traction of the second reel angular speed. The data contains 2.500 points sampled at 0.1𝑠, corresponding to 250𝑠. No documented motifs exist.
-
Jupyter-Notebook Functional near-infrared spectroscopy (fNIRS) contains brain imag- inary data recorded at 690𝑛𝑚 intensity. There are 208.028 measurements in total. The data is known to be a difficult example, as it contains four motion artifacts, due to movements of the patient, which dominate MD. No documented motifs exist.
-
Jupyter-Notebook Semi-Synthetic with implanted Ground Truth: One example series form our 25 semi-synthetic time series. To measure the precision of the different MD methods we created a semi-synthetic dataset using the first 25 datasets of an anomaly benchmark and implanted motif sets of varying sizes $k \in [5, \dots, 10]$ of fixed length $l=500$.
-
Jupyter-Notebook Full results for the Semi-Synthetic Dataset with implanted Ground Truth: To measure the precision of the different MD methods we created a semi-synthetic dataset using the first 25 datasets of an anomaly benchmark and implanted motif sets of varying sizes $k \in [5, \dots, 10]$ of fixed length $l=500$.
Citation
If you use this work, please cite as:
@article{motiflets2022,
title={Motiflets - Simple and Accurate Detection of Motifs in Time Series},
author={Schäfer, Patrick and Leser, Ulf},
journal={Proceedings of the VLDB Endowment},
volume={16},
number={4},
pages={725--737},
year={2022},
publisher={PVLDB}
}
Link to the paper.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.







