OPOF domains for online POMDP planning

Project description
opof-pomdp
OPOF online POMDP planning domains for 2D navigation under uncertainty. They include the optimization of macro-actions.

opof-pomdp is maintained by the Kavraki Lab at Rice University.
Installation
$ pip install opof-pomdp
opof-pomdp is officially tested and supported for Python 3.9, 3.10, 3.11 and Ubuntu 20.04, 22.04.
Domain: POMDPMacro[task,length]
from opof_pomdp.domains import POMDPMacro
# Creates a POMDPMacro domain instance for the "LightDark" task with macro-action length 8.
domain = POMDPMacro("LightDark", 8)
Description
We explore doing online POMDP planning for a specified task using the DESPOT online POMDP planner. The robot operates in a partially observable world, and tracks a belief over the world's state across actions that it has taken. Given the current belief at each step, the robot must determine a good action (which corresponds to moving a fixed distance toward some heading) to execute. It does so by running the DESPOT online POMDP planner. DESPOT runs some form of anytime Monte-Carlo tree search over possible action and observation sequences, rooted at the current belief, and returns a lower bound for the computed partial policy.
Planner optimization problem
Since the tree search is exponential in search depth, POMDPMacro[task,length] explores using open-loop macro-actions to improve the planning efficiency.
Here, DESPOT is parameterized with a set of $8$ macro-actions, which are 2D cubic Bezier curves stretched and discretized into $length$ number of line segments that
determine the heading of each corresponding action in the macro-action. Each Bezier curve is controlled by a control vector $\in \mathbb{R}^{2 \times 3}$, which determine the control points of the curve.
Since the shape of a Bezier curve is invariant up to a fixed constant across the control points, we constrain the control vector to lie on the unit sphere.
The planner optimization problem is to find a generator $G_\theta(c)$ that maps a problem instance (in this case, the combination of the current belief, represented as a particle filter, and the current task parameters,
whose representation depends on the task) to a joint control vector $\in \mathbb{R}^{8 \times 2 \times 3}$ (which determines the shape of the $8$ macro-actions), such that the lower bound value reported by DESPOT is maximized.
Planning objective
$\boldsymbol{f}(x; c)$ is given as the lower bound value reported by DESPOT, under a timeout of $100$ ms. When evaluating, we instead run the planner across $50$ episodes, at each step calling the generator, and compute the average sum of rewards (as opposed to considering the lower bound value for a single belief during training).
Problem instance distribution
For POMDPMacro[task,length], the distribution of problem instances is dynamic.
It is hard to prescribe a "dataset of beliefs" in online POMDP planning to construct a problem instance distribution.
The space of reachable beliefs is too hard to determine beforehand, and too small relative to the entire belief space to sample at random.
Instead, POMDPMacro[task,length] loops through episodes of planning and execution, returning the current task parameters and belief at the current step
whenever samples from the problem instance distribution are requested.
Tasks
LightDark
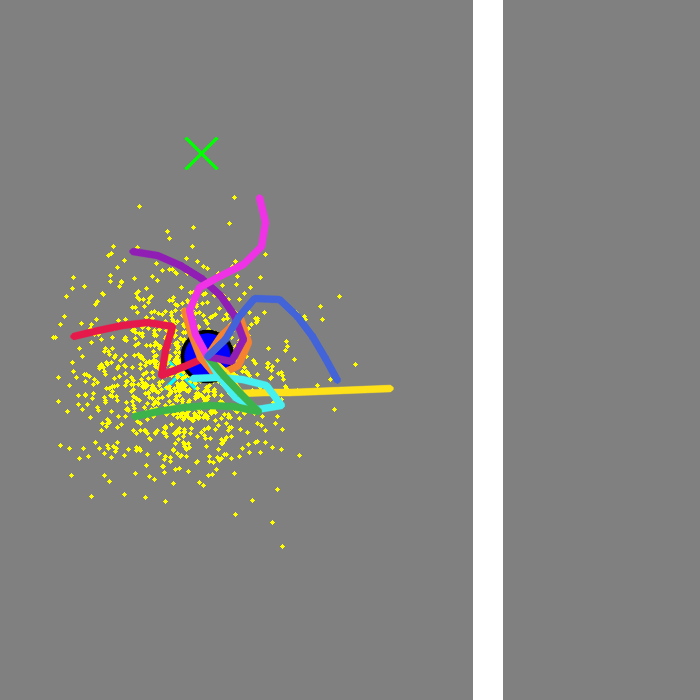
Description
The robot (blue circle) wants to move to and stop exactly at a goal location (green cross). However, it cannot observe its own position in the dark region (gray background), but can do so only in the light region (white vertical strip). It starts with uncertainty over its position (yellow particles) and should discover, through planning, that localizing against the light before attempting to stop at the goal will lead to a higher success rate, despite taking a longer route.
Task parameters
The task is parameterized by the goal position and the position of the light strip, which are uniformly selected.
Recommended length:
$8$ is the macro-action length known to be empirically optimal when training using GC.
PuckPush
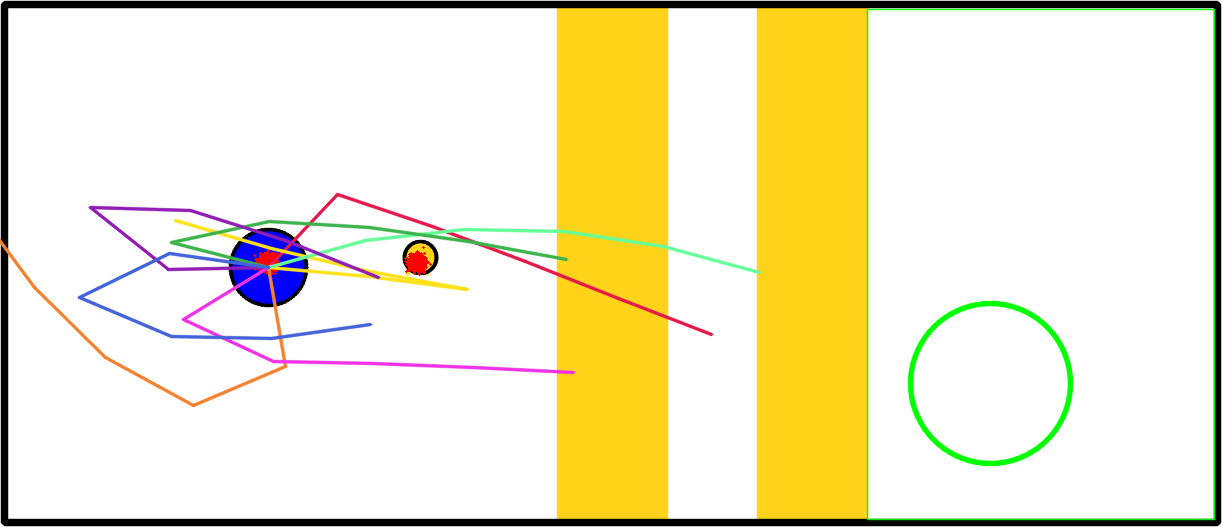
Description
A circular robot (blue) pushes a circular puck (yellow circle) toward a goal (green circle). The world has two vertical strips (yellow) which have the same color as the puck, preventing observations of the puck from being made when on top. The robot starts with little uncertainty (red particles) over its position and the puck's position corresponding to sensor noise, which grows as the puck moves across the vertical strips. Furthermore, since both robot and puck are circular, the puck slides across the surface of the robot whenever it is pushed. The robot must discover, through planning, an extremely long-horizon plan that can (i) recover localization of the puck, and can (ii) recover from the sliding effect by retracing to re-push the puck.
Task parameters
The task is parameterized by position of the goal region, which is uniformly selected within the white area on the right.
Recommended length:
$5$ is the macro-action length known to be empirically optimal when training using GC.
Citing
If you use opof-pomdp, please cite us with:
@article{lee23opof,
author = {Lee, Yiyuan and Lee, Katie and Cai, Panpan and Hsu, David and Kavraki, Lydia E.},
title = {The Planner Optimization Problem: Formulations and Frameworks},
booktitle = {arXiv},
year = {2023},
doi = {10.48550/ARXIV.2303.06768},
}
@inproceedings{lee21a,
AUTHOR = {Yiyuan Lee AND Panpan Cai AND David Hsu},
TITLE = {{MAGIC: Learning Macro-Actions for Online POMDP Planning }},
BOOKTITLE = {Proceedings of Robotics: Science and Systems},
YEAR = {2021},
ADDRESS = {Virtual},
MONTH = {July},
DOI = {10.15607/RSS.2021.XVII.041}
}
License
opof-pomdp is licensed under the BSD-3 license.
opof-pomdp includes a copy of the following libraries as dependencies. These copies are protected and distributed according to the corresponding original license.
- Boost (homepage): Boost Software License
- CARLA/SUMMIT (homepage): MIT
- DESPOT (homepage): GPLv3
- tomykira's Base64.h (homepage): MIT
- magic (homepage): MIT
- OpenCV (homepage): Apache 2.0
- GAMMA/RVO2 (homepage): Apache 2.0
opof-pomdp is maintained by the Kavraki Lab at Rice University, funded in part by NSF RI 2008720 and Rice University funds.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distributions
Hashes for opof_pomdp-0.2.1-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | c8f3face3a866f9ca0797ededc113f7bd8f3d79f35ebc02aad620b4c03e04f69 |
|
| MD5 | 3c053e4567b621af1a85fef38daf5acf |
|
| BLAKE2b-256 | b0523abbc5be45d271f2bde44238e12a92d1972872d08f4812a4041f5da78276 |
Hashes for opof_pomdp-0.2.1-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 3af780ee5b972136fcc2e6028d080fd546c1ad3f2250074f351df859c8a0b7ff |
|
| MD5 | 4e6aef3df60f7138a6303c7dd2d48554 |
|
| BLAKE2b-256 | bc30cb4e0bfb0e35b80e538a69f6caca1d6d830fbf2b68971f4fb0c160f45b5a |
Hashes for opof_pomdp-0.2.1-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 8afa1cc6edad06d766775cd4061ec569922dd4b57db7f710cd0fe8588af207d3 |
|
| MD5 | 152d811750b4c5889d706317f8061dcd |
|
| BLAKE2b-256 | edd2a093089d279c4c61c3cc1d3f1408320ab29885caf9608c7b14b681b3b166 |







