Parallel processing with progress bars

Project description
Parallelbar
Parallelbar displays the progress of tasks in the process pool for methods such as map, imap and imap_unordered. Parallelbar is based on the tqdm module and the standard python multiprocessing library.
Installation
pip install parallelbar
or
pip install --user git+https://github.com/dubovikmaster/parallelbar.git
Example
from parallelbar import progress_imap, progress_map, progress_imapu
from parallelbar.tools import cpu_bench, fibonacci
Let's create a list of 100 numbers and test progress_map with default parameters on a toy function cpu_bench:
tasks = [1_000_000 + i for i in range(100)]
%%time
list(map(cpu_bench, tasks))
Wall time: 52.6 s
Ok, by default this works on one core of my i7-9700F and it took 52 seconds. Let's parallelize the calculations for all 8 cores and look at the progress. This can be easily done by replacing standart function map with progress_map.
if __name__=='__main__':
progress_map(cpu_bench, tasks)

Core progress:
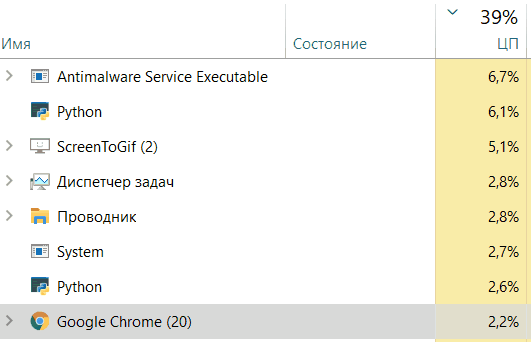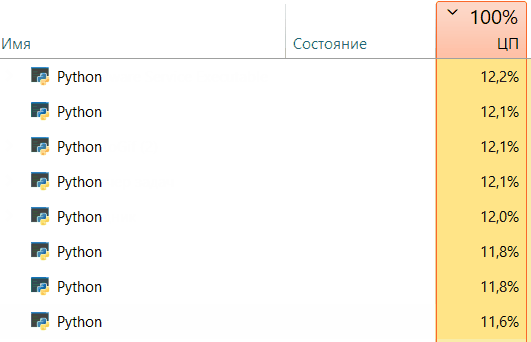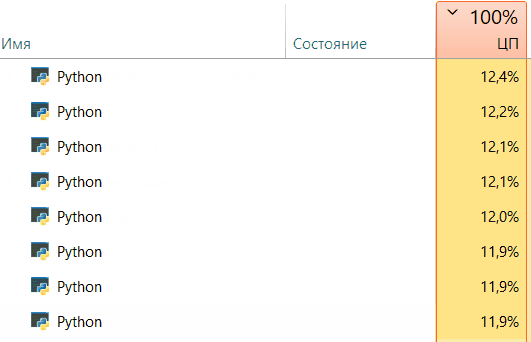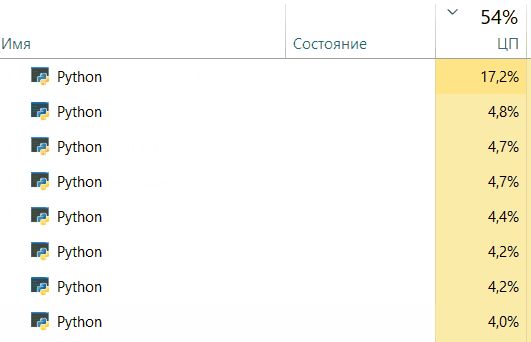
Great! We got an acceleration of 6 times! We were also able to observe the process What about the progress on the cores of your cpu?
if __name__=='__main__':
progress_map(cpu_bench, tasks, core_progress=True)
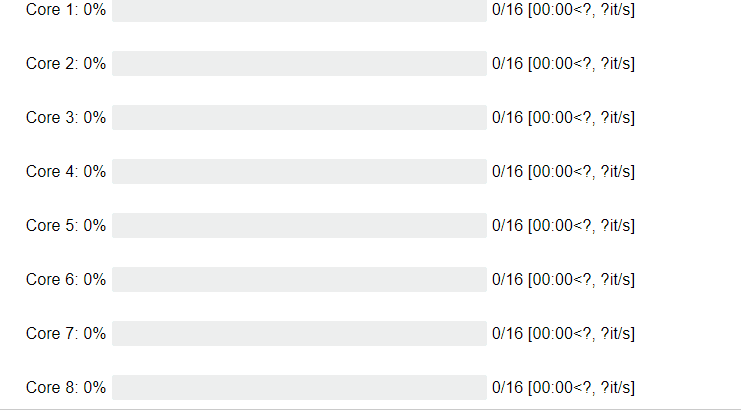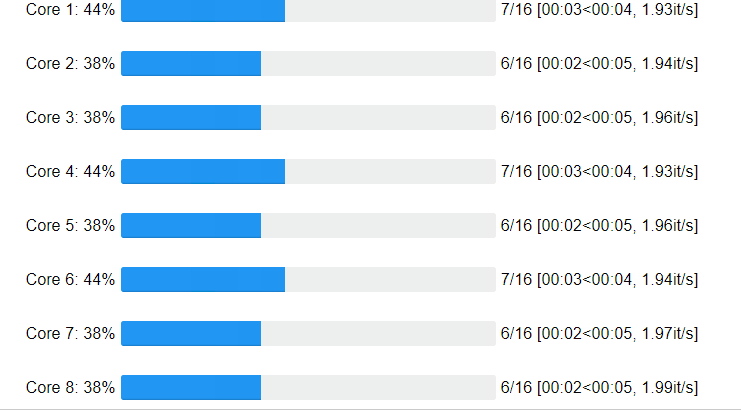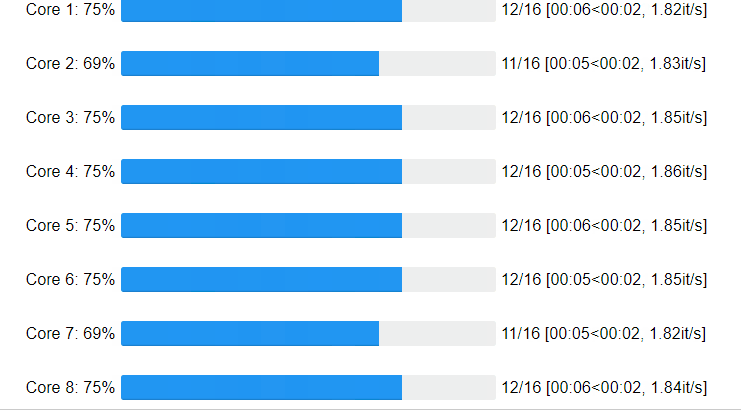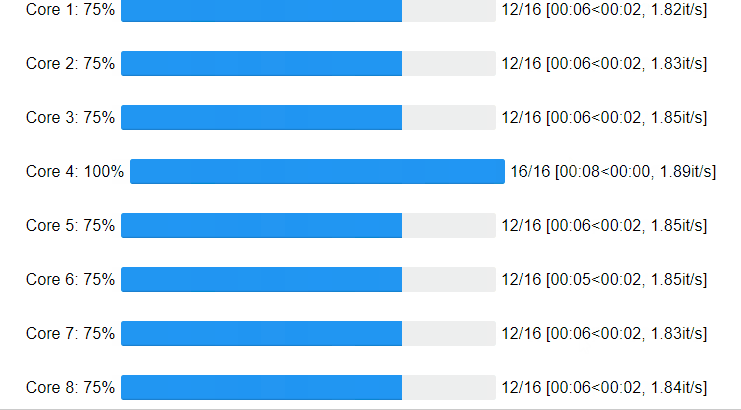
Ofcourse you can specify the number of cores and chunk_size:
if __name__=='__main__':
tasks = [5_000_00 + i for i in range(100)]
progress_map(cpu_bench, tasks, n_cpu=4, chunk_size=1, core_progress=True)

You can also easily use progress_imap and progress_imapu analogs of the imap and imap_unordered methods of the Pool() class
%%time
if __name__=='__main__':
tasks = [20 + i for i in range(15)]
result = progress_imap(fibonacci, tasks, chunk_size=1, core_progress=False)

Wall time: 2.08 s
result
[6765,
10946,
17711,
28657,
46368,
75025,
121393,
196418,
317811,
514229,
832040,
1346269,
2178309,
3524578,
5702887]
Problems of the naive approach
Why can't I do something simpler? Let's take the standard imap method and run through it in a loop with tqdm and take the results from the processes:
from multiprocessing import Pool
from tqdm.auto import tqdm
if __name__=='__main__':
with Pool() as p:
tasks = [20 + i for i in range(15)]
pool = p.imap(fibonacci, tasks)
result = []
for i in tqdm(pool, total=len(tasks)):
result.append(i)

It looks good, doesn't it? But let's do the following, make the first task very difficult for the core. To do this, I will insert the number 38 at the beginning of the tasks list. Let's see what happens
if __name__=='__main__':
with Pool() as p:
tasks = [20 + i for i in range(15)]
tasks.insert(1, 38)
pool = p.imap_unordered(fibonacci, tasks)
result = []
for i in tqdm(pool, total=len(tasks)):
result.append(i)

This is a fiasco. Our progress hung on the completion of the first task and then at the end showed 100% progress. Let's try to do the same experiment only for the progress_imap function:
if __name__=='__main__':
with Pool() as p:
tasks = [20 + i for i in range(15)]
tasks.insert(1, 38)
result = progress_imap(fibonacci, tasks)

The progress_imap function takes care of collecting the result and closing the process pool for you. In fact, the naive approach described above will work for the standard imap_unordered method. But it does not guarantee the order of the returned result. This is often critically important.
License
MIT license
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Hashes for parallelbar-0.1.17-py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | a3d174be522c89f1841341c34614a30e6be33263c1ee217da013938ec967b743 |
|
| MD5 | 5ffb28068216b3a3f130cd84a9091ecd |
|
| BLAKE2b-256 | 4fc8e0392d45b14b8b27d5e2758a8282590269de9684e1db72bfdb0d9d0fdc6e |







