Chinese text processing, representation, and visualization.

Project description
SimpleChinese




Chinese text processing, representation, and visualization.
Free software: MIT license
Documentation: https://simplechinese.readthedocs.io.
Features
Read the data from a csv file.
df = pd.read_csv("test.csv")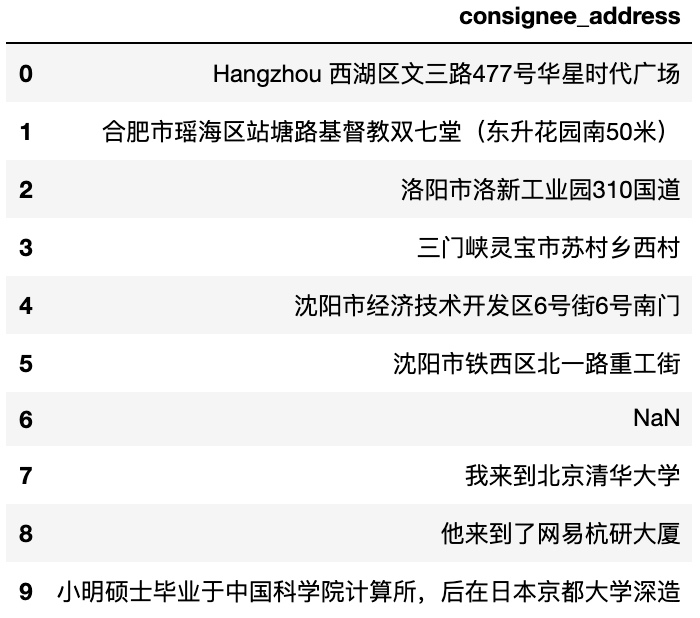
Clean the data.
sc.clean(df)
The clean function does the following:
fillna(): Fill the N/As in a pandas.DataFrame with an empty string.
toLower(): Transform alphabets to their lowercases.
remove_punctuations(): Remove all the punctuations in a string or a pandas.DataFrame.
remove_space(): Remove all the spaces in a string or a pandas.DataFrame.
Extract words from the data
sc.extract_words(sc.clean(df))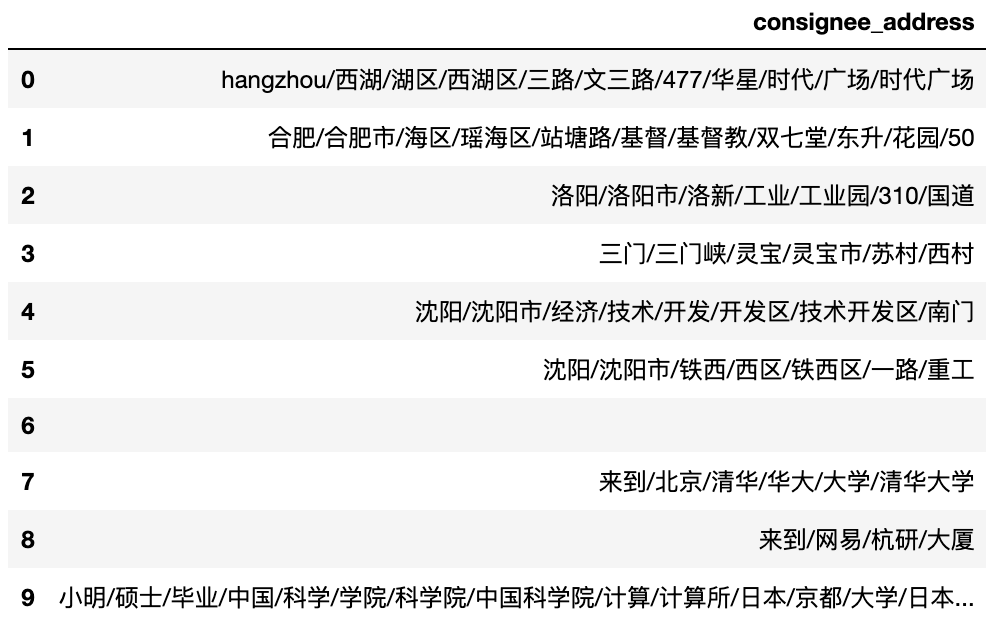
Vectorization
sc.pca(sc.tfidf(sc.clean(df).iloc[:,0]))
Word cloud
sc.wordcloud(sc.clean(df).iloc[:,0], font_path="yahei.ttc")
Credits
This package was created with Cookiecutter and the audreyr/cookiecutter-pypackage project template.
History
0.1.0 (2020-07-10)
First release on PyPI.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.







