Statistical IV: J-Divergence Hypothesis Test for the Information Value (IV)

Project description
Statistical IV
Statistical_IV: J-Divergence Hypothesis Test for the Information Value (IV). Calculation of the Information Value with specific limits to the predictive power.
Using optimalBinning, We created a specific way to calculate a predicitive power for each particular variable.
-
Import package
from statistical_iv import api
-
Provide a DataFrame as Input:
- Supply a DataFrame
dfcontaining your data for IV calculation.
- Supply a DataFrame
-
Specify Predictor Variables:
- Prived a list of predictor variable names (
variables_names) to analyze.
- Prived a list of predictor variable names (
-
Define the Target Variable:
- Specify the name of the target variable (
var_y) in your DataFrame.
- Specify the name of the target variable (
-
Indicate Variable Types:
- Define the type of your predictor variables as 'categorical' or 'numerical' using the
type_varsparameter.
- Define the type of your predictor variables as 'categorical' or 'numerical' using the
-
Optional: Set Maximum Bins:
- Adjust the maximum number of bins for discretization (optional) using the
max_binsparameter.
- Adjust the maximum number of bins for discretization (optional) using the
-
Call the
statistical_ivFunction:- Calculate IV by calling the
statistical_ivfunction with the specified parameters (That is used for OptimalBinning package).
result_df = statistical_iv(df, variables_names, var_y, type_vars, max_bins)
- Calculate IV by calling the
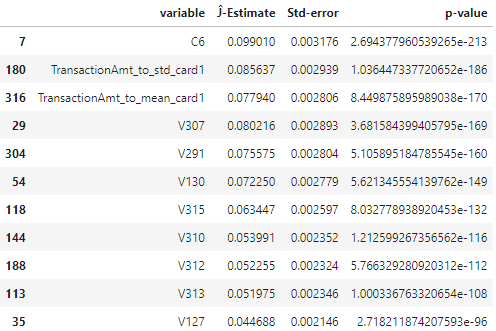
Example Result:
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
statistical_iv-0.2.8.tar.gz
(5.1 kB
view hashes)
Built Distribution
Close
Hashes for statistical_iv-0.2.8-py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 8089548f368408d2b6f3b0d9070d1d66fb0b8af3810b03a9c82056ceac905aae |
|
| MD5 | 5db09789437bd53b4ec238416bceab94 |
|
| BLAKE2b-256 | 3523061a90e08afa6a003e70ee64868116e04c9da5a65939f3be590e5c4974a3 |







