A utility library for working with Table Schema in Python



Project description
tableschema-py





A library for working with Table Schema in Python.
Features
Tableto work with data tables described by Table SchemaSchemarepresenting Table SchemaFieldrepresenting Table Schema fieldvalidateto validate Table Schemainferto infer Table Schema from data- built-in command-line interface to validate and infer schemas
- storage/plugins system to connect tables to different storage backends like SQL Database
Gettings Started
Installation
The package use semantic versioning. It means that major versions could include breaking changes. It's highly recommended to specify tableschema version range in your setup/requirements file e.g. tableschema>=1.0,<2.0.
$ pip install tableschema
Examples
Code examples in this readme requires Python 3.4+ interpreter. You could see even more example in examples directory.
from tableschema import Table
# Create table
table = Table('path.csv', schema='schema.json')
# Print schema descriptor
print(table.schema.descriptor)
# Print cast rows in a dict form
for keyed_row in table.iter(keyed=True):
print(keyed_row)
Documentation
Table
A table is a core concept in a tabular data world. It represents a data with a metadata (Table Schema). Let's see how we could use it in practice.
Consider we have some local csv file. It could be inline data or remote link - all supported by Table class (except local files for in-brower usage of course). But say it's data.csv for now:
city,location
london,"51.50,-0.11"
paris,"48.85,2.30"
rome,N/A
Let's create and read a table. We use static Table.load method and table.read method with a keyed option to get array of keyed rows:
table = Table('data.csv')
table.headers # ['city', 'location']
table.read(keyed=True)
# [
# {city: 'london', location: '51.50,-0.11'},
# {city: 'paris', location: '48.85,2.30'},
# {city: 'rome', location: 'N/A'},
# ]
As we could see our locations are just a strings. But it should be geopoints. Also Rome's location is not available but it's also just a N/A string instead of JavaScript null. First we have to infer Table Schema:
table.infer()
table.schema.descriptor
# { fields:
# [ { name: 'city', type: 'string', format: 'default' },
# { name: 'location', type: 'geopoint', format: 'default' } ],
# missingValues: [ '' ] }
table.read(keyed=True)
# Fails with a data validation error
Let's fix not available location. There is a missingValues property in Table Schema specification. As a first try we set missingValues to N/A in table.schema.descriptor. Schema descriptor could be changed in-place but all changes sould be commited by table.schema.commit():
table.schema.descriptor['missingValues'] = 'N/A'
table.schema.commit()
table.schema.valid # false
table.schema.errors
# [<ValidationError: "'N/A' is not of type 'array'">]
As a good citiziens we've decided to check out schema descriptor validity. And it's not valid! We sould use an array for missingValues property. Also don't forget to have an empty string as a missing value:
table.schema.descriptor['missingValues'] = ['', 'N/A']
table.schema.commit()
table.schema.valid # true
All good. It looks like we're ready to read our data again:
table.read(keyed=True)
# [
# {city: 'london', location: [51.50,-0.11]},
# {city: 'paris', location: [48.85,2.30]},
# {city: 'rome', location: null},
# ]
Now we see that:
- locations are arrays with numeric lattide and longitude
- Rome's location is a native Python
None
And because there are no errors on data reading we could be sure that our data is valid againt our schema. Let's save it:
table.schema.save('schema.json')
table.save('data.csv')
Our data.csv looks the same because it has been stringified back to csv format. But now we have schema.json:
{
"fields": [
{
"name": "city",
"type": "string",
"format": "default"
},
{
"name": "location",
"type": "geopoint",
"format": "default"
}
],
"missingValues": [
"",
"N/A"
]
}
If we decide to improve it even more we could update the schema file and then open it again. But now providing a schema path:
table = Table('data.csv', schema='schema.json')
# Continue the work
It was onle basic introduction to the Table class. To learn more let's take a look on Table class API reference.
Table(source, schema=None, strict=False, post_cast=[], storage=None, **options)
Constructor to instantiate Table class. If references argument is provided foreign keys will be checked on any reading operation.
source (str/list[])- data source (one of):- local file (path)
- remote file (url)
- array of arrays representing the rows
schema (any)- data schema in all forms supported bySchemaclassstrict (bool)- strictness option to pass toSchemaconstructorpost_cast (function[])- list of post cast processorsstorage (None/str)- storage name likesqlorbigqueryoptions (dict)-tabulatoror storage options(exceptions.TableSchemaException)- raises any error occured in table creation process(Table)- returns data table class instance
table.headers
(str[])- returns data source headers
table.schema
(Schema)- returns schema class instance
table.iter(keyed=Fase, extended=False, cast=True, relations=False)
Iter through the table data and emits rows cast based on table schema. Data casting could be disabled.
keyed (bool)- iter keyed rowsextended (bool)- iter extended rowscast (bool)- disable data casting if falserelations (dict)- dict of foreign key references in a form of{resource1: [{field1: value1, field2: value2}, ...], ...}. If provided foreign key fields will checked and resolved to its references(exceptions.TableSchemaException)- raises any error occured in this process(any[]/any{})- yields rows:[value1, value2]- base{header1: value1, header2: value2}- keyed[rowNumber, [header1, header2], [value1, value2]]- extended
table.read(keyed=False, extended=False, cast=True, relations=False, limit=None)
Read the whole table and returns as array of rows. Count of rows could be limited.
keyed (bool)- flag to emit keyed rowsextended (bool)- flag to emit extended rowscast (bool)- flag to disable data casting if falserelations (dict)- dict of foreign key references in a form of{resource1: [{field1: value1, field2: value2}, ...], ...}. If provided foreign key fields will checked and resolved to its referenceslimit (int)- integer limit of rows to return(exceptions.TableSchemaException)- raises any error occured in this process(list[])- returns array of rows (seetable.iter)
table.infer(limit=100, confidence=0.75)
Infer a schema for the table. It will infer and set Table Schema to table.schema based on table data.
limit (int)- limit rows sample sizeconfidence (float)- how many casting errors are allowed (as a ratio, between 0 and 1)(dict)- returns Table Schema descriptor
table.save(target, storage=None, **options)
To save schema use
table.schema.save()
Save data source to file locally in CSV format with , (comma) delimiter
target (str)- saving target (e.g. file path)storage (None/str)- storage name likesqlorbigqueryoptions (dict)-tabulatoror storage options(exceptions.TableSchemaException)- raises an error if there is saving problem(True/Storage)- returns true or storage instance
Schema
A model of a schema with helpful methods for working with the schema and supported data. Schema instances can be initialized with a schema source as a url to a JSON file or a JSON object. The schema is initially validated (see validate below). By default validation errors will be stored in schema.errors but in a strict mode it will be instantly raised.
Let's create a blank schema. It's not valid because descriptor.fields property is required by the Table Schema specification:
schema = Schema()
schema.valid # false
schema.errors
# [<ValidationError: "'fields' is a required property">]
To do not create a schema descriptor by hands we will use a schema.infer method to infer the descriptor from given data:
schema.infer([
['id', 'age', 'name'],
['1','39','Paul'],
['2','23','Jimmy'],
['3','36','Jane'],
['4','28','Judy'],
])
schema.valid # true
schema.descriptor
#{ fields:
# [ { name: 'id', type: 'integer', format: 'default' },
# { name: 'age', type: 'integer', format: 'default' },
# { name: 'name', type: 'string', format: 'default' } ],
# missingValues: [ '' ] }
Now we have an inferred schema and it's valid. We could cast data row against our schema. We provide a string input by an output will be cast correspondingly:
schema.cast_row(['5', '66', 'Sam'])
# [ 5, 66, 'Sam' ]
But if we try provide some missing value to age field cast will fail because for now only one possible missing value is an empty string. Let's update our schema:
schema.cast_row(['6', 'N/A', 'Walt'])
# Cast error
schema.descriptor['missingValues'] = ['', 'N/A']
schema.commit()
schema.cast_row(['6', 'N/A', 'Walt'])
# [ 6, None, 'Walt' ]
We could save the schema to a local file. And we could continue the work in any time just loading it from the local file:
schema.save('schema.json')
schema = Schema('schema.json')
It was onle basic introduction to the Schema class. To learn more let's take a look on Schema class API reference.
Schema(descriptor, strict=False)
Constructor to instantiate Schema class.
descriptor (str/dict)- schema descriptor:- local path
- remote url
- dictionary
strict (bool)- flag to alter validation behaviour:- if false error will not be raised and all error will be collected in
schema.errors - if strict is true any validation error will be raised immediately
- if false error will not be raised and all error will be collected in
(exceptions.TableSchemaException)- raises any error occured in the process(Schema)- returns schema class instance
schema.valid
(bool)- returns validation status. It always true in strict mode.
schema.errors
(Exception[])- returns validation errors. It always empty in strict mode.
schema.descriptor
(dict)- returns schema descriptor
schema.primary_key
(str[])- returns schema primary key
schema.foreign_keys
(dict[])- returns schema foreign keys
schema.fields
(Field[])- returns an array ofFieldinstances
schema.field_names
(str[])- returns an array of field names.
schema.get_field(name)
Get schema field by name.
name (str)- schema field name(Field/None)- returnsFieldinstance or null if not found
schema.add_field(descriptor)
Add new field to schema. The schema descriptor will be validated with newly added field descriptor.
descriptor (dict)- field descriptor(exceptions.TableSchemaException)- raises any error occured in the process(Field/None)- returns addedFieldinstance or null if not added
schema.remove_field(name)
Remove field resource by name. The schema descriptor will be validated after field descriptor removal.
name (str)- schema field name(exceptions.TableSchemaException)- raises any error occured in the process(Field/None)- returns removedFieldinstances or null if not found
schema.cast_row(row)
Cast row based on field types and formats.
row (any[])- data row as an array of values(any[])- returns cast data row
schema.infer(rows, headers=1, confidence=0.75)
Infer and set schema.descriptor based on data sample.
rows (list[])- array of arrays representing rows.headers (int/str[])- data sample headers (one of):- row number containing headers (
rowsshould contain headers rows) - array of headers (
rowsshould NOT contain headers rows)
- row number containing headers (
confidence (float)- how many casting errors are allowed (as a ratio, between 0 and 1){dict}- returns Table Schema descriptor
schema.commit(strict=None)
Update schema instance if there are in-place changes in the descriptor.
strict (bool)- alterstrictmode for further work(exceptions.TableSchemaException)- raises any error occured in the process(bool)- returns true on success and false if not modified
descriptor = {'fields': [{'name': 'field', 'type': 'string'}]}
schema = Schema(descriptor)
schema.getField('name')['type'] # string
schema.descriptor.fields[0]['type'] = 'number'
schema.getField('name')['type'] # string
schema.commit()
schema.getField('name')['type'] # number
schema.save(target)
Save schema descriptor to target destination.
target (str)- path where to save a descriptor(exceptions.TableSchemaException)- raises any error occured in the process(bool)- returns true on success
Field
from tableschema import Field
# Init field
field = Field({'name': 'name', type': 'number'})
# Cast a value
field.cast_value('12345') # -> 12345
Data values can be cast to native Python objects with a Field instance. Type instances can be initialized with field descriptors. This allows formats and constraints to be defined.
Casting a value will check the value is of the expected type, is in the correct format, and complies with any constraints imposed by a schema. E.g. a date value (in ISO 8601 format) can be cast with a DateType instance. Values that can't be cast will raise an InvalidCastError exception.
Casting a value that doesn't meet the constraints will raise a ConstraintError exception.
Here is an API reference for the Field class:
new Field(descriptor, missingValues=[''])
Constructor to instantiate Field class.
descriptor (dict)- schema field descriptormissingValues (str[])- an array with string representing missing values(exceptions.TableSchemaException)- raises any error occured in the process(Field)- returns field class instance
field.name
(str)- returns field name
field.type
(str)- returns field type
field.format
(str)- returns field format
field.required
(bool)- returns true if field is required
field.constraints
(dict)- returns an object with field constraints
field.descriptor
(dict)- returns field descriptor
field.castValue(value, constraints=true)
Cast given value according to the field type and format.
value (any)- value to cast against fieldconstraints (boll/str[])- gets constraints configuration- it could be set to true to disable constraint checks
- it could be an Array of constraints to check e.g. ['minimum', 'maximum']
(exceptions.TableSchemaException)- raises any error occured in the process(any)- returns cast value
field.testValue(value, constraints=true)
Test if value is compliant to the field.
value (any)- value to cast against fieldconstraints (bool/str[])- constraints configuration(bool)- returns if value is compliant to the field
validate
Given a schema as JSON file, url to JSON file, or a Python dict, validate returns True for a valid Table Schema, or raises an exception, exceptions.ValidationError. It validates only schema, not data against schema!
from tableschema import validate, exceptions
try:
valid = validate(descriptor)
except exceptions.ValidationError as exception:
for error in exception.errors:
# handle individual error
validate(descriptor)
Validate a Table Schema descriptor.
descriptor (str/dict)- schema descriptor (one of):- local path
- remote url
- object
- (exceptions.ValidationError) - raises on invalid
(bool)- returns true on valid
infer
Given headers and data, infer will return a Table Schema as a Python dict based on the data values. Given the data file, data_to_infer.csv:
id,age,name
1,39,Paul
2,23,Jimmy
3,36,Jane
4,28,Judy
Let's call infer for this file:
from tableschema import infer
descriptor = infer('data_to_infer.csv')
#{'fields': [
# {
# 'format': 'default',
# 'name': 'id',
# 'type': 'integer'
# },
# {
# 'format': 'default',
# 'name': 'age',
# 'type': 'integer'
# },
# {
# 'format': 'default',
# 'name': 'name',
# 'type': 'string'
# }]
#}
The number of rows used by infer can be limited with the limit argument.
infer(source, headers=1, limit=100, confidence=0.75, **options)
Infer source schema.
source (any)- source as path, url or inline dataheaders (int/str[])- headers rows number or headers listconfidence (float)- how many casting errors are allowed (as a ratio, between 0 and 1)(exceptions.TableSchemaException)- raises any error occured in the process(dict)- returns schema descriptor
Exceptions
exceptions.TableSchemaException
Base class for all library exceptions. If there are multiple errors it could be read from an exceptions object:
try:
# lib action
except exceptions.TableSchemaException as exception:
if exception.multiple:
for error in exception.errors:
# handle error
exceptions.LoadError
All loading errors.
exceptions.ValidationError
All validation errors.
exceptions.CastError
All value cast errors.
exceptions.RelationError
All integrity errors.
exceptions.StorageError
All storage errors.
Storage
The library includes interface declaration to implement tabular Storage. This interface allow to use different data storage systems like SQL with tableschema.Table class (load/save) as well as on the data package level:
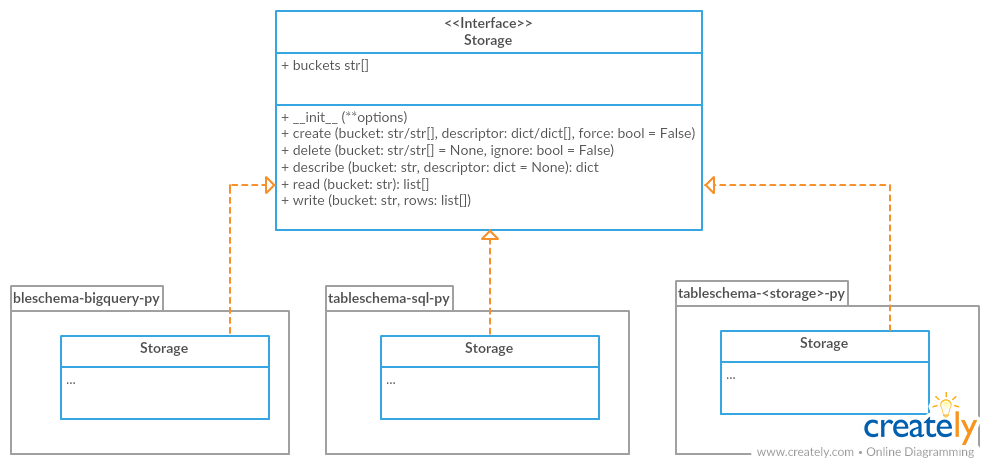
For instantiation of concrete storage instances tableschema.Storage provides a unified factory method connect (under the hood the plugin system will be used):
# pip install tableschema_sql
from tableschema import Storage
storage = Storage.connect('sql', **options)
storage.create('bucket', descriptor)
storage.write('bucket', rows)
storage.read('bucket')
Storage.connect(name, **options)
Create tabular storage based on storage name.
name (str)- storage name likesqloptions (dict)- concrete storage options(exceptions.StorageError)- raises on any error(Storage)- returnsStorageinstance
An implementor should follow tableschema.Storage interface to write his own storage backend. Concrete storage backends could include additional functionality specific to conrete storage system. See plugins system below to know how to integrate custom storage plugin into your workflow.
<<Interface>>Storage(**options)
Create tabular storage. Implementations should fully implement this interface to be compatible to Storage API.
options (dict)- concrete storage options(exceptions.StorageError)- raises on any error(Storage)- returnsStorageinstance
storage.buckets
Return list of storage bucket names. A bucket is a special term which has almost the same meaning as the term table. You should consider bucket as a table stored in the storage.
(exceptions.StorageError)- raises on any errorstr[]- return list of bucket names
create(bucket, descriptor, force=False)
Create one/multiple buckets.
bucket (str/list)- bucket name or list of bucket namesdescriptor (dict/dict[])- schema descriptor or list of descriptorsforce (bool)- delete and re-create already existent buckets(exceptions.StorageError)- raises on any error
delete(bucket=None, ignore=False)
Delete one/multiple/all buckets.
bucket (str/list/None)- bucket name or list of bucket names to delete. If None all buckets will be deleteddescriptor (dict/dict[])- schema descriptor or list of descriptorsignore (bool)- don't raise an error on non-existent bucket deletion from storage(exceptions.StorageError)- raises on any error
describe(bucket, descriptor=None)
Get/set bucket's Table Schema descriptor.
bucket (str)- bucket namedescriptor (dict/None)- schema descriptor to set(exceptions.StorageError)- raises on any error(dict)- returns Table Schema descriptor
iter(bucket)
This method should iter typed values based on the schema of this bucket.
bucket (str)- bucket name(exceptions.StorageError)- raises on any error(list[])- yields data rows
read(bucket)
This method should read typed values based on the schema of this bucket.
bucket (str)- bucket name(exceptions.StorageError)- raises on any error(list[])- returns data rows
write(bucket, rows)
This method writes data rows into the storage. It should store values of unsupported types as strings internally (like csv does).
bucket (str)- bucket namerows (list[])- data rows to write(exceptions.StorageError)- raises on any error
Plugins
Table Schema has a plugin system. Any package with the name like tableschema_<name> could be imported as:
from tableschema.plugins import <name>
If a plugin is not installed ImportError will be raised with a message describing how to install the plugin.
Official plugins
CLI
It's a provisional API excluded from SemVer. If you use it as a part of other program please pin concrete
tableschemaversion to your requirements file.
Table Schema features a CLI called tableschema. This CLI exposes the infer and validate functions for command line use.
Example of validate usage:
$ tableschema validate path/to-schema.json
Example of infer usage:
$ tableschema infer path/to/data.csv
The response is a schema as JSON. The optional argument --encoding allows a character encoding to be specified for the data file. The default is utf-8.
Contributing
The project follows the Open Knowledge International coding standards.
Recommended way to get started is to create and activate a project virtual environment. To install package and development dependencies into active environment:
$ make install
To run tests with linting and coverage:
$ make test
For linting pylama configured in pylama.ini is used. On this stage it's already
installed into your environment and could be used separately with more fine-grained control
as described in documentation - https://pylama.readthedocs.io/en/latest/.
For example to sort results by error type:
$ pylama --sort <path>
For testing tox configured in tox.ini is used.
It's already installed into your environment and could be used separately with more fine-grained control as described in documentation - https://testrun.org/tox/latest/.
For example to check subset of tests against Python 2 environment with increased verbosity.
All positional arguments and options after -- will be passed to py.test:
tox -e py27 -- -v tests/<path>
Under the hood tox uses pytest configured in pytest.ini, coverage
and mock packages. This packages are available only in tox envionments.
Changelog
Here described only breaking and the most important changes. The full changelog and documentation for all released versions could be found in nicely formatted commit history.
v1.3
- Support datetime with no time for date casting
v1.2
- Support floats like 1.0 for integer casting
v1.1
- Added the
confidenceparameter toinfer
v1.0
- The library has been rebased on the Frictionless Data specs v1 - https://frictionlessdata.io/specs/table-schema/
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Hashes for tableschema-1.3.2-py2.py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 0bf6b879e94f370d0a6c2d31dcc6621547b73e8d87a0653cea7eca1d0da522c2 |
|
| MD5 | e77875c9342a2b731a5660dc7a5263ee |
|
| BLAKE2b-256 | aa845b098aed454c7f4fa95673ddbbfa1ef47a29187f791a8e4a11566c34f45e |







