Scrape top GitHub repositories and users based on keyword

Project description
Top Github Users Scraper
Scrape top Github repositories and users based on keywords.

Setup
Installation
pip install top-github-scraper
Add Credentials
To make sure you can scrape many repositories and users, add your GitHub's credentials to .env file.
touch .env
Add your username and token to .env file:
GITHUB_USERNAME=yourusername
GITHUB_TOKEN=yourtoken
Usage
Get Top Github Repositories' URLs
from top_github_scraper import get_top_urls
get_top_repos(keyword="machine learning", stop_page=20)
After running the script above, a file named
top_repo_urls_<keyword>_<start_page>_<end_page>.json
will be saved to your current directory.
Get Top Github Repositories' Information
from top_github_scraper import get_top_urls
get_top_urls("machine learning", stop_page=20)
After running the script above, 2 files named
top_repo_urls_<keyword>_<start_page>_<end_page>.jsontop_repo_info_<keyword>_<start_page>_<end_page>.json
will be saved to your current directory.
Get Top Github Users' Profiles
from top_github_scraper import get_top_users
get_top_users("machine learning", stop_page=20)
After running the script above, 3 files named
top_repo_urls_<keyword>_<start_page>_<end_page>.jsontop_repo_info_<keyword>_<start_page>_<end_page>.jsontop_user_info_<keyword>_<start_page>_<end_page>.csv
will be saved to your current directory.
Parameters
- get_top_urls
keyword: str Keyword to search for (.i.e, machine learning)save_path: str, optional where to save the output file, by default"top_repo_urls"start_page: int, optional page number to start scraping from, by default0stop_page: int, optional page number of the last page to scrape, by default50
- get_top_repos
keyword: str Keyword to search for (.i.e, machine learning)max_n_top_contributors: int number of top contributors in each repository to scrape from, by default10start_page: int, optional page number to start scraping from, by default0stop_page: int, optional page number of the last page to scrape, by default50url_save_path: str, optional where to save the output file of URLs, by default"top_repo_urls"repo_save_path: str, optional where to save the output file of repositories' information, by default"top_repo_info"
- get_top_users
keyword: str Keyword to search for (.i.e, machine learning)max_n_top_contributors: int number of top contributors in each repository to scrape from, by default10start_page: int, optional page number to start scraping from, by default0stop_page: int, optional page number of the last page to scrape, by default50url_save_path: str, optional where to save the output file of URLs, by default"top_repo_urls"repo_save_path: str, optional where to save the output file of repositories' information, by default"top_repo_info"user_save_path: str, optional where to save the output file of users' profiles, by default"top_user_info"
How the Data is Scraped
top-github-scraper scrapes the owners as well as the contributors of the top repositories that pop up in the search when searching for a specific keyword on GitHub.
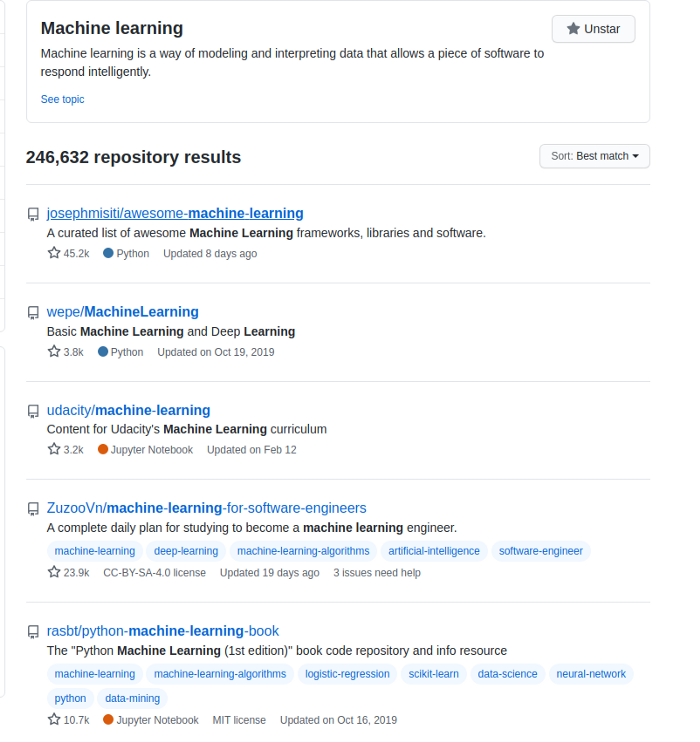
top-github-scraper scrapes 16 data points:
login: usernameurl: URL of the usercontributions: Number of contributions to the repository that the user is scraped fromstargazers_count: Number of stars of the repository that the user is scraped fromforks_count: Number of forks of the repository that the user is scraped fromtype: Whether this account is a user or an organizationname: Name of the usercompany: User's companylocation: User's locationemail: User's emailhireable: Whether the user is hireablebio: Short description of the userpublic_repos: Number of public repositories the user has (including forked repositories)public_gists: Number of public repositories the user has (including forked gists)followers: Number of followers the user hasfollowing: Number of people the user is following
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Hashes for top-github-scraper-0.1.0.4.tar.gz
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | b1a46ffebcbcf76e86d2a3e2a41bb3db5900b3bff38e3720f98cb186b55d9d3d |
|
| MD5 | 8ad1fb3275017b8fc70e1fa11fab6fdd |
|
| BLAKE2b-256 | 1aba236411f3f8fe883850f0bad04dabd242c195371d44aa8340483eac511685 |
Hashes for top_github_scraper-0.1.0.4-py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | c69fd9081b9c9b07b3ad0228b2f4b6d299a26b503e4b51458743ce056cee0c9d |
|
| MD5 | 860e2177db13b8cfe6d38b6e6eca71ad |
|
| BLAKE2b-256 | 9b83f0ed288a9c958e59f0b40f432d1f13e8b9c12f1ec2876749204ccfe9c330 |







