Python library for streamlined tracking and management of AI training processes.

Project description
SwanLab在线版 · 文档 · 微信 · 报告问题 · 建议反馈 · 更新日志










👋🏻 什么是SwanLab
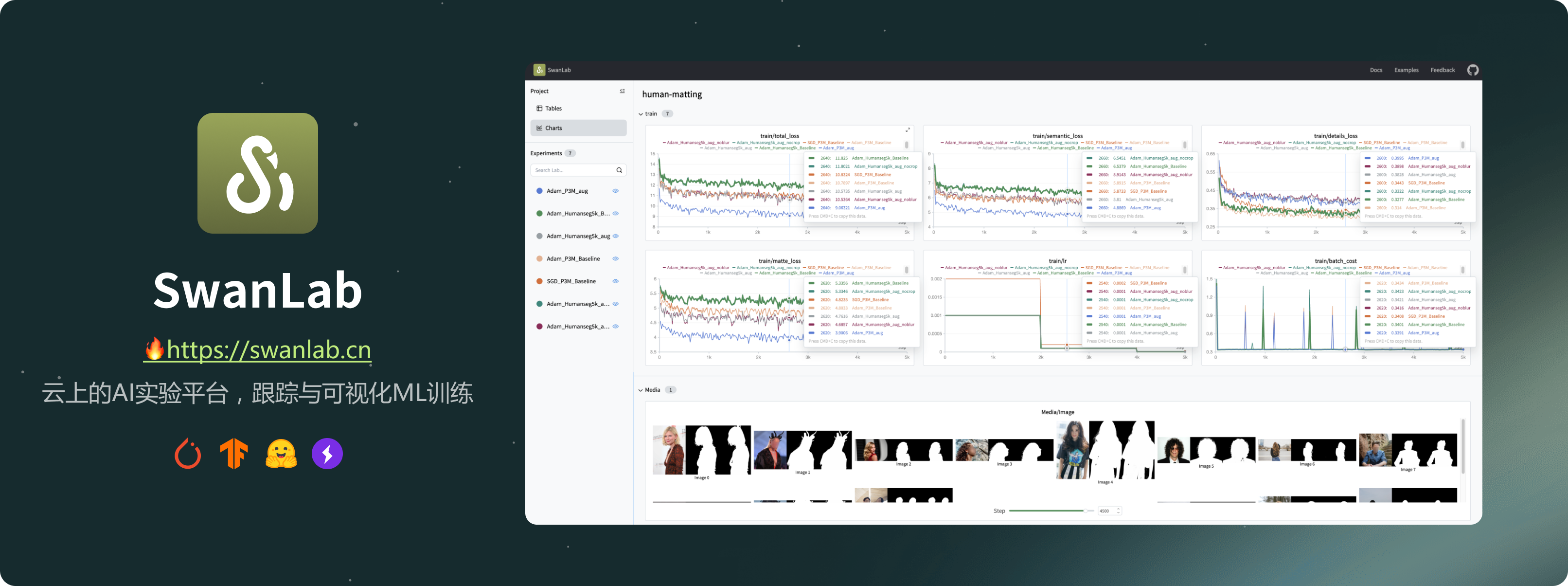
SwanLab is an open-source, lightweight AI experiment tracking tool that provides a platform for tracking, comparing, and collaborating on experiments, aiming to accelerate the research and development efficiency of AI teams by 100 times.
SwanLab是一款开源、轻量级的AI实验跟踪工具,提供了一个跟踪、比较、和协作实验的平台,旨在加速AI研发团队100倍的研发效率。
其提供了友好的API和漂亮的界面,结合了超参数跟踪、指标记录、在线协作、实验链接分享、实时消息通知等功能,让您可以快速跟踪ML实验、可视化过程、分享给同伴。
借助SwanLab,科研人员可以沉淀自己的每一次训练经验,与合作者无缝地交流和协作,机器学习工程师可以更快地开发可用于生产的模型。

以下是其核心特性列表:
1. 📊实验指标与超参数跟踪: 极简的代码嵌入您的机器学习pipeline,跟踪记录训练关键指标
- 自由的超参数与实验配置记录
- 支持的元数据类型:标量指标、图像、音频、文本、...
- 支持的图表类型:折线图、媒体图(图像、音频、文本)、...
- 自动记录:控制台logging、GPU硬件、Git信息、Python解释器、Python库列表、代码目录
2. ⚡️全面的框架集成: PyTorch、Tensorflow、PyTorch Lightning、🤗HuggingFace Transformers、MMEngine、OpenAI、ZhipuAI、Hydra、...
3. 📦组织实验: 集中式仪表板,快速管理多个项目与实验,通过整体视图速览训练全局
4. 🆚比较结果: 通过在线表格与对比图表比较不同实验的超参数和结果,挖掘迭代灵感
5. 👥在线协作: 您可以与团队进行协作式训练,支持将实验实时同步在一个项目下,您可以在线查看团队的训练记录,基于结果发表看法与建议
6. ✉️分享结果: 复制和发送持久的URL来共享每个实验,方便地发送给伙伴,或嵌入到在线笔记中
7. 💻支持自托管: 支持不联网使用,自托管的社区版同样可以查看仪表盘与管理实验
[!IMPORTANT]
收藏项目,你将从 GitHub 上无延迟地接收所有发布通知~⭐️

🏁 快速开始
1.安装
pip install swanlab
2.登录并获取API Key
swanlab login
出现提示时,输入您的API Key,按下回车,完成登陆。
3.将SwanLab与你的代码集成
import swanlab
# 初始化一个新的swanlab实验
swanlab.init(
project="my-first-ml",
config={'learning-rate': 0.003}
)
# 记录指标
for i in range(10):
swanlab.log({"loss": i})
大功告成!前往SwanLab查看你的第一个SwanLab实验。
📃 更多案例
MNIST
import os
import torch
from torch import nn, optim, utils
import torch.nn.functional as F
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
import swanlab
# CNN网络构建
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
# 1,28x28
self.conv1 = nn.Conv2d(1, 10, 5) # 10, 24x24
self.conv2 = nn.Conv2d(10, 20, 3) # 128, 10x10
self.fc1 = nn.Linear(20 * 10 * 10, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
in_size = x.size(0)
out = self.conv1(x) # 24
out = F.relu(out)
out = F.max_pool2d(out, 2, 2) # 12
out = self.conv2(out) # 10
out = F.relu(out)
out = out.view(in_size, -1)
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
out = F.log_softmax(out, dim=1)
return out
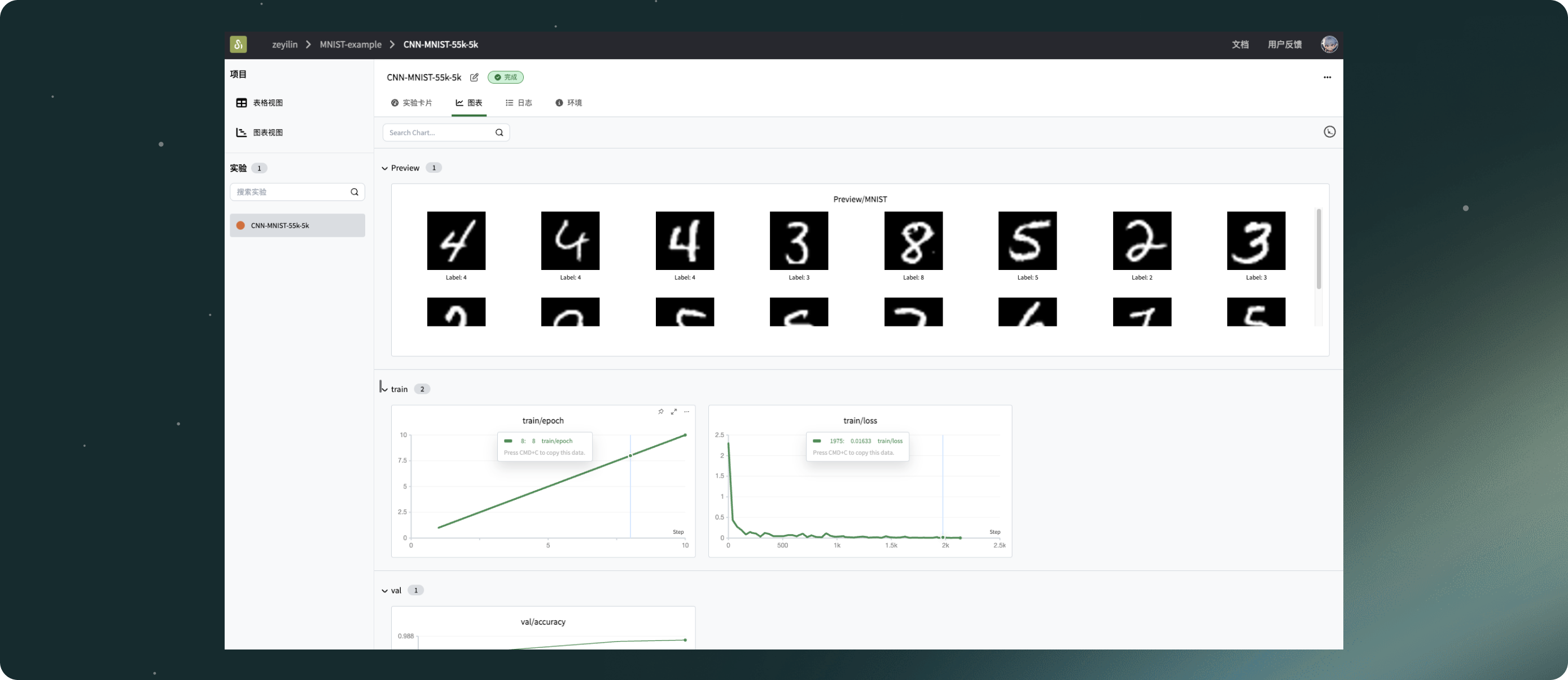
# 捕获并可视化前20张图像
def log_images(loader, num_images=16):
images_logged = 0
logged_images = []
for images, labels in loader:
# images: batch of images, labels: batch of labels
for i in range(images.shape[0]):
if images_logged < num_images:
# 使用swanlab.Image将图像转换为wandb可视化格式
logged_images.append(swanlab.Image(images[i], caption=f"Label: {labels[i]}"))
images_logged += 1
else:
break
if images_logged >= num_images:
break
swanlab.log({"MNIST-Preview": logged_images})
if __name__ == "__main__":
# 初始化swanlab
run = swanlab.init(
project="MNIST-example",
experiment_name="ConvNet",
description="Train ConvNet on MNIST dataset.",
config={
"model": "CNN",
"optim": "Adam",
"lr": 0.001,
"batch_size": 512,
"num_epochs": 10,
"train_dataset_num": 55000,
"val_dataset_num": 5000,
},
)
# 设置训练机、验证集和测试集
dataset = MNIST(os.getcwd(), train=True, download=True, transform=ToTensor())
train_dataset, val_dataset = utils.data.random_split(
dataset, [run.config.train_dataset_num, run.config.val_dataset_num]
)
train_loader = utils.data.DataLoader(train_dataset, batch_size=run.config.batch_size, shuffle=True)
val_loader = utils.data.DataLoader(val_dataset, batch_size=1, shuffle=False)
# 初始化模型、损失函数和优化器
model = ConvNet()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=run.config.lr)
# (可选)看一下数据集的前16张图像
log_images(train_loader, 16)
# 开始训练
for epoch in range(1, run.config.num_epochs):
swanlab.log({"train/epoch": epoch})
# 训练循环
for iter, batch in enumerate(train_loader):
x, y = batch
optimizer.zero_grad()
output = model(x)
loss = criterion(output, y)
loss.backward()
optimizer.step()
print(
f"Epoch [{epoch}/{run.config.num_epochs}], Iteration [{iter + 1}/{len(train_loader)}], Loss: {loss.item()}"
)
if iter % 20 == 0:
swanlab.log({"train/loss": loss.item()}, step=(epoch - 1) * len(train_loader) + iter)
# 每4个epoch验证一次
if epoch % 2 == 0:
model.eval()
correct = 0
total = 0
with torch.no_grad():
for batch in val_loader:
x, y = batch
output = model(x)
_, predicted = torch.max(output, 1)
total += y.size(0)
correct += (predicted == y).sum().item()
accuracy = correct / total
swanlab.log({"val/accuracy": accuracy})
FashionMNSIT-ResNet34
import os
import torch
from torch import nn, optim, utils
import torch.nn.functional as F
from torchvision.datasets import FashionMNIST
from torchvision.transforms import ToTensor
import swanlab
# ResNet网络构建
class Basicblock(nn.Module):
def __init__(self, in_planes, planes, stride=1):
super(Basicblock, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=in_planes, out_channels=planes, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(planes),
nn.ReLU()
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=planes, out_channels=planes, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(planes),
)
if stride != 1 or in_planes != planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels=in_planes, out_channels=planes, kernel_size=3, stride=stride, padding=1),
nn.BatchNorm2d(planes)
)
else:
self.shortcut = nn.Sequential()
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_block, num_classes):
super(ResNet, self).__init__()
self.in_planes = 16
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(16),
nn.ReLU()
)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.block1 = self._make_layer(block, 16, num_block[0], stride=1)
self.block2 = self._make_layer(block, 32, num_block[1], stride=2)
self.block3 = self._make_layer(block, 64, num_block[2], stride=2)
# self.block4 = self._make_layer(block, 512, num_block[3], stride=2)
self.outlayer = nn.Linear(64, num_classes)
def _make_layer(self, block, planes, num_block, stride):
layers = []
for i in range(num_block):
if i == 0:
layers.append(block(self.in_planes, planes, stride))
else:
layers.append(block(planes, planes, 1))
self.in_planes = planes
return nn.Sequential(*layers)
def forward(self, x):
x = self.maxpool(self.conv1(x))
x = self.block1(x) # [200, 64, 28, 28]
x = self.block2(x) # [200, 128, 14, 14]
x = self.block3(x) # [200, 256, 7, 7]
# out = self.block4(out)
x = F.avg_pool2d(x, 7) # [200, 256, 1, 1]
x = x.view(x.size(0), -1) # [200,256]
out = self.outlayer(x)
return out
# 捕获并可视化前20张图像
def log_images(loader, num_images=16):
images_logged = 0
logged_images = []
for images, labels in loader:
# images: batch of images, labels: batch of labels
for i in range(images.shape[0]):
if images_logged < num_images:
# 使用swanlab.Image将图像转换为wandb可视化格式
logged_images.append(swanlab.Image(images[i], caption=f"Label: {labels[i]}", size=(128, 128)))
images_logged += 1
else:
break
if images_logged >= num_images:
break
swanlab.log({"Preview/MNIST": logged_images})
if __name__ == "__main__":
# 设置device
try:
use_mps = torch.backends.mps.is_available()
except AttributeError:
use_mps = False
if torch.cuda.is_available():
device = "cuda"
elif use_mps:
device = "mps"
else:
device = "cpu"
# 初始化swanlab
run = swanlab.init(
project="FashionMNIST",
workspace="SwanLab",
experiment_name="Resnet18-Adam",
config={
"model": "Resnet34",
"optim": "Adam",
"lr": 0.001,
"batch_size": 32,
"num_epochs": 10,
"train_dataset_num": 55000,
"val_dataset_num": 5000,
"device": device,
"num_classes": 10,
},
)
# 设置训练机、验证集和测试集
dataset = FashionMNIST(os.getcwd(), train=True, download=True, transform=ToTensor())
train_dataset, val_dataset = utils.data.random_split(
dataset, [run.config.train_dataset_num, run.config.val_dataset_num]
)
train_loader = utils.data.DataLoader(train_dataset, batch_size=run.config.batch_size, shuffle=True)
val_loader = utils.data.DataLoader(val_dataset, batch_size=1, shuffle=False)
# 初始化模型、损失函数和优化器
if run.config.model == "Resnet18":
model = ResNet(Basicblock, [1, 1, 1, 1], 10)
elif run.config.model == "Resnet34":
model = ResNet(Basicblock, [2, 3, 5, 2], 10)
elif run.config.model == "Resnet50":
model = ResNet(Basicblock, [3, 4, 6, 3], 10)
model.to(torch.device(device))
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=run.config.lr)
# (可选)看一下数据集的前16张图像
log_images(train_loader, 16)
# 开始训练
for epoch in range(1, run.config.num_epochs + 1):
swanlab.log({"train/epoch": epoch}, step=epoch)
# 训练循环
for iter, batch in enumerate(train_loader):
x, y = batch
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
output = model(x)
loss = criterion(output, y)
loss.backward()
optimizer.step()
if iter % 40 == 0:
print(
f"Epoch [{epoch}/{run.config.num_epochs}], Iteration [{iter + 1}/{len(train_loader)}], Loss: {loss.item()}"
)
swanlab.log({"train/loss": loss.item()}, step=(epoch - 1) * len(train_loader) + iter)
# 每4个epoch验证一次
if epoch % 2 == 0:
model.eval()
correct = 0
total = 0
with torch.no_grad():
for batch in val_loader:
x, y = batch
x, y = x.to(device), y.to(device)
output = model(x)
_, predicted = torch.max(output, 1)
total += y.size(0)
correct += (predicted == y).sum().item()
accuracy = correct / total
swanlab.log({"val/accuracy": accuracy}, step=epoch)
💻 自托管
自托管社区版支持离线查看SwanLab仪表盘。
离线实验跟踪
在swanlab.init中设置logir和cloud这两个参数,即可离线跟踪实验:
...
swanlab.init(
logdir='./logs',
cloud=False,
)
...
-
参数
cloud设置为False,关闭将实验同步到云端 -
参数
logdir的设置是可选的,它的作用是指定了SwanLab日志文件的保存位置(默认保存在swanlog文件夹下)- 日志文件会在跟踪实验的过程中被创建和更新,离线看板的启动也将基于这些日志文件
其他部分和云端使用完全一致。
开启离线看板
打开终端,使用下面的指令,开启一个SwanLab仪表板:
swanlab watch -l ./logs
运行完成后,SwanLab会给你1个本地的URL链接(默认是http://127.0.0.1:5092)
访问该链接,就可以在浏览器用离线看板查看实验了。
🚗 框架集成
将您最喜欢的框架与SwanLab结合使用,更多集成。
⚡️ PyTorch Lightning
使用SwanLabLogger创建示例,并代入Trainer的logger参数中,即可实现SwanLab记录训练指标。
from swanlab.integration.pytorch_lightning import SwanLabLogger
import importlib.util
import os
import pytorch_lightning as pl
from torch import nn, optim, utils
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
encoder = nn.Sequential(nn.Linear(28 * 28, 128), nn.ReLU(), nn.Linear(128, 3))
decoder = nn.Sequential(nn.Linear(3, 128), nn.ReLU(), nn.Linear(128, 28 * 28))
class LitAutoEncoder(pl.LightningModule):
def __init__(self, encoder, decoder):
super().__init__()
self.encoder = encoder
self.decoder = decoder
def training_step(self, batch, batch_idx):
# training_step defines the train loop.
# it is independent of forward
x, y = batch
x = x.view(x.size(0), -1)
z = self.encoder(x)
x_hat = self.decoder(z)
loss = nn.functional.mse_loss(x_hat, x)
# Logging to TensorBoard (if installed) by default
self.log("train_loss", loss)
return loss
def test_step(self, batch, batch_idx):
# test_step defines the test loop.
# it is independent of forward
x, y = batch
x = x.view(x.size(0), -1)
z = self.encoder(x)
x_hat = self.decoder(z)
loss = nn.functional.mse_loss(x_hat, x)
# Logging to TensorBoard (if installed) by default
self.log("test_loss", loss)
return loss
def configure_optimizers(self):
optimizer = optim.Adam(self.parameters(), lr=1e-3)
return optimizer
# init the autoencoder
autoencoder = LitAutoEncoder(encoder, decoder)
# setup data
dataset = MNIST(os.getcwd(), train=True, download=True, transform=ToTensor())
train_dataset, val_dataset = utils.data.random_split(dataset, [55000, 5000])
test_dataset = MNIST(os.getcwd(), train=False, download=True, transform=ToTensor())
train_loader = utils.data.DataLoader(train_dataset)
val_loader = utils.data.DataLoader(val_dataset)
test_loader = utils.data.DataLoader(test_dataset)
swanlab_logger = SwanLabLogger(
project="swanlab_example",
experiment_name="example_experiment",
cloud=False,
)
trainer = pl.Trainer(limit_train_batches=100, max_epochs=5, logger=swanlab_logger)
trainer.fit(model=autoencoder, train_dataloaders=train_loader, val_dataloaders=val_loader)
trainer.test(dataloaders=test_loader)
🤗HuggingFace Transformers
使用SwanLabCallback创建示例,并代入Trainer的callbacks参数中,即可实现SwanLab记录训练指标。
import evaluate
import numpy as np
import swanlab
from swanlab.integration.huggingface import SwanLabCallback
from datasets import load_dataset
from transformers import AutoModelForSequenceClassification, AutoTokenizer, Trainer, TrainingArguments
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
dataset = load_dataset("yelp_review_full")
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
tokenized_datasets = dataset.map(tokenize_function, batched=True)
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
metric = evaluate.load("accuracy")
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
training_args = TrainingArguments(
output_dir="test_trainer",
report_to="none",
num_train_epochs=3,
logging_steps=50,
)
swanlab_callback = SwanLabCallback(experiment_name="TransformersTest", cloud=False)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
callbacks=[swanlab_callback],
)
trainer.train()
🆚 与熟悉的工具的比较
Tensorboard vs SwanLab
-
☁️支持在线使用: 通过SwanLab可以方便地将训练实验在云端在线同步与保存,便于远程查看训练进展、管理历史项目、分享实验链接、发送实时消息通知、多端看实验等。而Tensorboard是一个离线的实验跟踪工具。
-
👥多人协作: 在进行多人、跨团队的机器学习协作时,通过SwanLab可以轻松管理多人的训练项目、分享实验链接、跨空间交流讨论。而Tensorboard主要为个人设计,难以进行多人协作和分享实验。
-
💻持久、集中的仪表板: 无论你在何处训练模型,无论是在本地计算机上、在实验室集群还是在公有云的GPU实例中,你的结果都会记录到同一个集中式仪表板中。而使用TensorBoard需要花费时间从不同的机器复制和管理 TFEvent文件。
-
💪更强大的表格: 通过SwanLab表格可以查看、搜索、过滤来自不同实验的结果,可以轻松查看数千个模型版本并找到适合不同任务的最佳性能模型。 TensorBoard 不适用于大型项目。
Weights and Biases vs SwanLab
-
Weights and Biases 是一个必须联网使用的闭源MLOps平台
-
SwanLab 不仅支持联网使用,也支持开源、免费、自托管的版本
🛣️ Roadmap
工具在迭代与反馈中进化~,欢迎提交功能建议
两周内即将上线
Table: 更灵活的多维表格图表,适用于LLM、AIGC、模型评估等场景- 邮件通知📧: 训练意外中断、训练完成、自定义情况等场景触达时,发送通知邮件
三个月内规划上线
Molecule: 生物化学分子可视化图表Plot: 自由的图表绘制方式Api: 通过API访问SwanLab数据- 系统硬件记录: 记录GPU、CPU、磁盘、网络等一系列硬件情况
- 代码记录: 记录训练代码
- 更多集成: LightGBM、XGBoost、openai、chatglm、mm系列、...)
- ...
长期关注
- 最有利于AI团队创新的协同方式
- 最友好的UI交互
- 移动端看实验
👥 社区
社区与支持
- GitHub Issues:使用SwanLab时遇到的错误和问题
- 电子邮件支持:反馈关于使用SwanLab的问题
- 微信交流群:交流使用SwanLab的问题、分享最新的AI技术
SwanLab README徽章
如果你喜欢在工作中使用 SwanLab,请将 SwanLab 徽章添加到你的README中:

[](https://github.com/swanhubx/swanlab)
在论文中引用SwanLab
如果您发现 SwanLab 对您的研究之旅有帮助,请考虑以下列格式引用:
@software{Zeyilin_SwanLab_2023,
author = {Zeyi Lin, Shaohong Chen, Kang Li, Qiushan Jiang, Zirui Cai, Kaifang Ji and {The SwanLab team}},
license = {Apache-2.0},
title = {{SwanLab}},
url = {https://github.com/swanhubx/swanlab},
year = {2023}
}
为SwanLab做出贡献
考虑为SwanLab做出贡献吗?首先,请花点时间阅读 贡献指南。
同时,我们非常欢迎通过社交媒体、活动和会议的分享来支持SwanLab,衷心感谢!
下载Icon
Contributors

📃 协议
本仓库遵循 Apache 2.0 License 开源协议
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.








{kind=link}