Extend LLMs to infinite length without sacrificing efficiency and performance, without retraining

Project description
Attention Sinks in Transformers for Infinite-length LLMs
| Llama 2 7B | Falcon-7B |
|---|---|
 |
 |
Overview
- Extend existing LLMs (e.g. Llama 2) to infinite length without sacrificing efficiency and performance, without any retraining.
- The
attention_sinksAPI allows for a drop-in replacement of thetransformersAPI:from attention_sinks import AutoModel model = AutoModel.from_pretrained("meta-llama/Llama-2-7b-hf", device_map="auto")
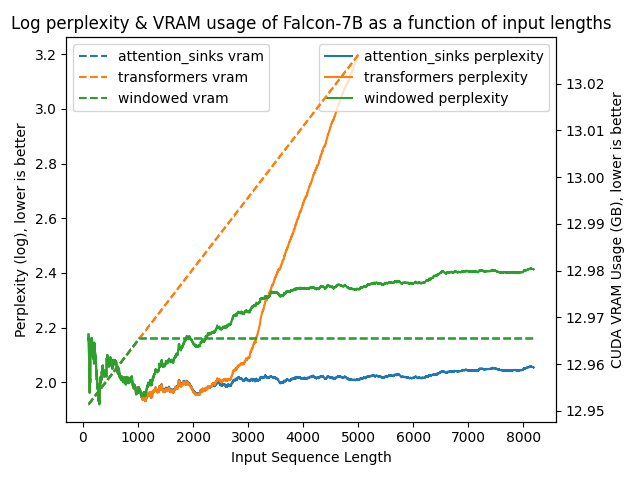
- Support for Llama and Falcon models.
- New parameters to
AutoModel....from_pretrained:attention_sink_size, int, defaults to 4: The number of initial tokens to use as the attention sink. These tokens are always included in the Attention Sink KV Cache.attention_sink_window_size, int, defaults to 1020: The size of the sliding window, i.e. the number of "recent tokens" to include in the Attention Sink KV Cache.
Installation
You can install attention_sinks like so
pip install attention_sinks
Benchmarks
You can run a few benchmarks to compute the perplexity of various models over time using the provided perplexity.py benchmarking script. For example:
python benchmark/perplexity.py --experiment attention_sinks
Full argument list
usage: perplexity.py [-h] [--experiment {attention_sinks,transformers,windowed}] [--model_name_or_path MODEL_NAME_OR_PATH] [--revision REVISION]
[--trust_remote_code] [--dataset_name DATASET_NAME] [--data_column DATA_COLUMN] [--task TASK] [--split {validation,test}]
[--num_tokens NUM_TOKENS] [--output_dir OUTPUT_DIR] [--window_size WINDOW_SIZE] [--attention_sink_size ATTENTION_SINK_SIZE]
options:
-h, --help show this help message and exit
--experiment {attention_sinks,transformers,windowed}
--model_name_or_path MODEL_NAME_OR_PATH
--revision REVISION
--trust_remote_code
--dataset_name DATASET_NAME
--data_column DATA_COLUMN
--task TASK
--split {validation,test}
--num_tokens NUM_TOKENS
--output_dir OUTPUT_DIR
--window_size WINDOW_SIZE
--attention_sink_size ATTENTION_SINK_SIZE
This script will create a csv file in the output directory ("benchmarks/outputs" by default) for that experiment, with information about perplexities, CUDA VRAM usage and latencies.
This information can be plotted using the plot_perplexity.py script. For example:
python benchmark/plot_perplexity.py --features perplexity latency --title "Log perplexity & latency of Llama 2 7B as a function of input lengths"
Full argument list
usage: plot_perplexity.py [-h] [--output_dir OUTPUT_DIR] [--features {perplexity,vram,latency} [{perplexity,vram,latency} ...]] [--title TITLE]
[--log_perplexity_limit LOG_PERPLEXITY_LIMIT] [--skip_first SKIP_FIRST]
options:
-h, --help show this help message and exit
--output_dir OUTPUT_DIR
--features {perplexity,vram,latency} [{perplexity,vram,latency} ...]
--title TITLE
--log_perplexity_limit LOG_PERPLEXITY_LIMIT
--skip_first SKIP_FIRST
This script takes all csv files from the output directory ("benchmark/outputs" by default), and creates a plot like so:
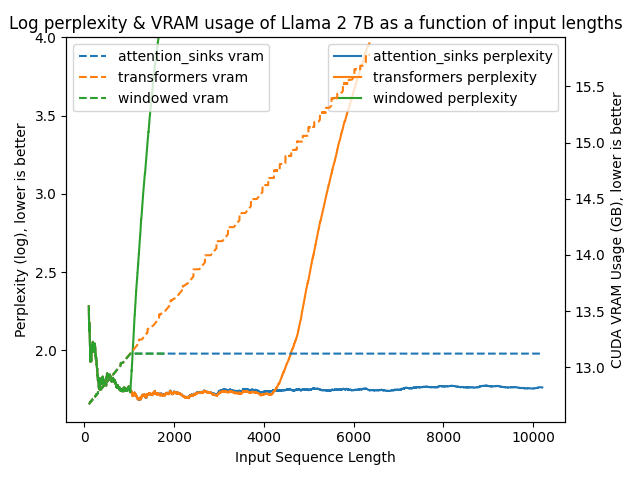
python benchmark/plot_perplexity.py --features perplexity vram --title "Log perplexity & VRAM usage of Llama 2 7B as a function of input lengths" --output_dir benchmark/outputs_llama_2_7b --log_perplexity_limit 4
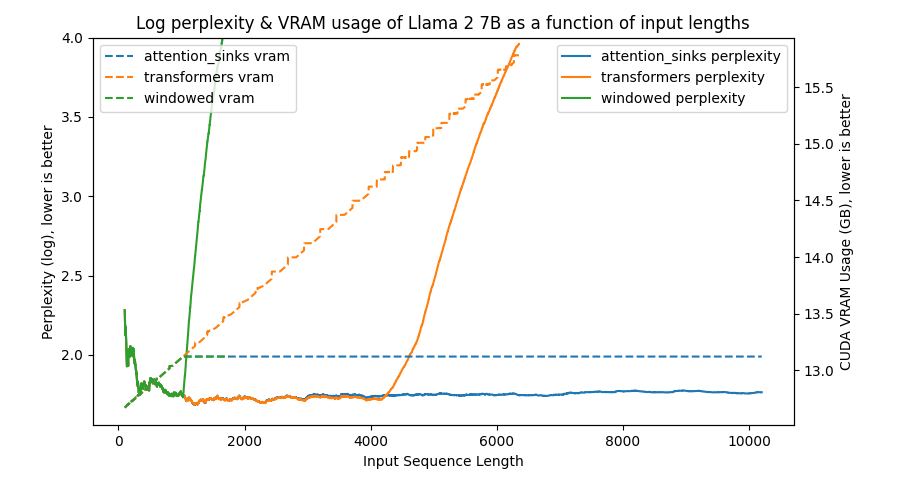
Clear as day:
transformers: The VRAM usage is linear as it doesn't do any windowing. The performance heavily falls after ~4096 tokens.windowed: The VRAM is constant usage due to the windowing at 1024 tokens. However, it fails as soon as the first tokens leave the window.attention_sinks: Constant VRAM usage due to windowing with 4 attention sink tokens + the 1020 most recent tokens. This approach never fails despite the constant VRAM usage.
I've uploaded benchmark/outputs_llama_2_7b so you can reproduce this graph using the former command.
Changelog
See CHANGELOG.md for all release information.
Credits
Inspired by, and adapted from StreamingLLM.
Citation
@article{xiao2023streamingllm,
title={Efficient Streaming Language Models with Attention Sinks},
author={Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike},
journal={arXiv},
year={2023}
}


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Hashes for attention_sinks-0.1.0-py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | d39adc01663526bba2379cd3b8afa298d4188b49f1fc6b26b7977dbe9d2739e6 |
|
| MD5 | d857f9ebc6adc3897e5ad4c05b6ce9e8 |
|
| BLAKE2b-256 | af579ba47c603785d5ab02e2330985cae9bcf330247e90b7a201aba8ea3f788d |







