Extend LLMs to infinite length without sacrificing efficiency and performance, without retraining

Project description
Attention Sinks in Transformers for Infinite-length LLMs
| Llama 2 7B | Falcon 7B |
|---|---|
 |
 |
| MPT 7B | Pythia 6.9B |
 |
 |
| Mistral 7B | |
 |
Overview
This repository is an open-source implementation of the Efficient Streaming Language Models with Attention Sinks paper.
- Extend existing LLMs (e.g. Llama 2) to infinite length without sacrificing efficiency and performance, without any retraining.
- Model perplexities were stable even after 4 million tokens!
- Unlike with regular
transformers, memory usage is constant and thus the inference does not get extremely slow due to memory issues at higher sequence lengths. - Models using attention sinks have been shown to perform very well at the task of recalling a value from 20 lines back, even if the model has already processed hundreds of thousands of lines, whereas models using regular dense or window attention fall to 0% after having processed a few thousand tokens.
- The
attention_sinksAPI allows for a drop-in replacement of thetransformersAPI:from attention_sinks import AutoModel model = AutoModel.from_pretrained("meta-llama/Llama-2-7b-hf", device_map="auto")
- Support for Llama, Falcon, MPT, GPTNeoX (Pythia) and Mistral models.
- New parameters to
AutoModel....from_pretrained:attention_sink_size,int, defaults to 4: The number of initial tokens to use as the attention sink. These tokens are always included in the Attention Sink KV Cache.attention_sink_window_size,int, defaults to 1020: The size of the sliding window, i.e. the number of "recent tokens" to include in the Attention Sink KV Cache. A larger window size costs more memory.
Installation
You can install attention_sinks like so
pip install attention_sinks
Usage
Loading any Llama, Falcon, MPT, GPTNeoX (Pythia) or Mistral model is as simple as loading it in transformers, the only change is that the model class must be imported from attention_sinks rather than transformers, e.g.:
from attention_sinks import AutoModel
model = AutoModel.from_pretrained("mosaicml/mpt-7b", device_map="auto")
Generation can be done like you would expect from transformers, e.g. like so:
import torch
from transformers import AutoTokenizer, TextStreamer, GenerationConfig
from attention_sinks import AutoModelForCausalLM
# model_id = "meta-llama/Llama-2-7b-hf"
# model_id = "mistralai/Mistral-7B-v0.1"
model_id = "mosaicml/mpt-7b"
# model_id = "tiiuae/falcon-7b"
# model_id = "EleutherAI/pythia-6.9b-deduped"
# Note: instruct or chat models also work.
# Load the chosen model and corresponding tokenizer
model = AutoModelForCausalLM.from_pretrained(
model_id,
# for efficiency:
device_map="auto",
torch_dtype=torch.float16,
# `attention_sinks`-specific arguments:
attention_sink_size=4,
attention_sink_window_size=252, # <- Low for the sake of faster generation
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
# Our input text
text = "Vaswani et al. (2017) introduced the Transformers"
# Encode the text
input_ids = tokenizer.encode(text, return_tensors="pt").to(model.device)
# Print tokens as they're being generated
streamer = TextStreamer(tokenizer)
generated_tokens = model.generate(
input_ids,
generation_config=GenerationConfig(
# use_cache=True is required, the rest can be changed up.
use_cache=True,
min_new_tokens=100_000,
max_new_tokens=1_000_000,
penalty_alpha=0.6,
top_k=5,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
),
streamer=streamer,
)
# Decode the final generated text
output_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
This example will happily generate between 100k and 1m tokens without forgetting how to speak, even on a low-VRAM environment like Google Colab when using load_in_4bit=True in the AutoModelForCausalLM.from_pretrained.
Benchmarks
Pre-prepared benchmarks
See benchmark/scripts for a collection of ready-to-go scripts for various model architectures like Llama 2, Falcon, MPT and GPT-NeoX (Pythia). Each of these scripts runs the benchmarking and plotting tools described below for pure transformers, attention_sinks and a third alternative: windowed, which involves simple windowed attention at a window size of 1024 tokens. Upon completion, the script will plot the figures that you see at the top of this README.
Benchmarking tool
You can run a few benchmarks to compute the perplexity of various models over time using the provided perplexity.py benchmarking script. This is done by computing the negative log likelihood losses of the chosen model when it is provided a full book with 60k+ tokens. By default, the scripts stop after 8192 tokens, but this can be modified. An ideal solution continuously has a low log perplexity and a constant CUDA VRAM usage.
To use the script, you can run:
python benchmark/perplexity.py --experiment attention_sinks
Full argument list
usage: perplexity.py [-h] [--experiment {attention_sinks,transformers,windowed}] [--model_name_or_path MODEL_NAME_OR_PATH] [--revision REVISION]
[--trust_remote_code] [--dataset_name DATASET_NAME] [--data_column DATA_COLUMN] [--task TASK] [--split {validation,test}]
[--num_tokens NUM_TOKENS] [--output_dir OUTPUT_DIR] [--window_size WINDOW_SIZE] [--attention_sink_size ATTENTION_SINK_SIZE]
options:
-h, --help show this help message and exit
--experiment {attention_sinks,transformers,windowed}
--model_name_or_path MODEL_NAME_OR_PATH
--revision REVISION
--trust_remote_code
--dataset_name DATASET_NAME
--data_column DATA_COLUMN
--task TASK
--split {validation,test}
--num_tokens NUM_TOKENS
--output_dir OUTPUT_DIR
--window_size WINDOW_SIZE
--attention_sink_size ATTENTION_SINK_SIZE
This script will create a csv file in the output directory ("benchmarks/outputs" by default) for that experiment, with information about perplexities, CUDA VRAM usage and latencies.
Plotting tool
The information from the benchmarking tool can be plotted using the plot_perplexity.py script. In particular, you can plot any combination of the following features:
perplexity,vram, i.e. CUDA VRAM usage,latency.
For example:
python benchmark/plot_perplexity.py --features perplexity latency --title "Log perplexity & latency of Llama 2 7B as a function of input lengths"
Full argument list
usage: plot_perplexity.py [-h] [--output_dir OUTPUT_DIR] [--features {perplexity,vram,latency} [{perplexity,vram,latency} ...]] [--title TITLE]
[--log_perplexity_limit LOG_PERPLEXITY_LIMIT] [--skip_first SKIP_FIRST]
options:
-h, --help show this help message and exit
--output_dir OUTPUT_DIR
--features {perplexity,vram,latency} [{perplexity,vram,latency} ...]
--title TITLE
--log_perplexity_limit LOG_PERPLEXITY_LIMIT
--skip_first SKIP_FIRST
This script takes all csv files from the output directory ("benchmark/outputs" by default), and creates a plot like so:
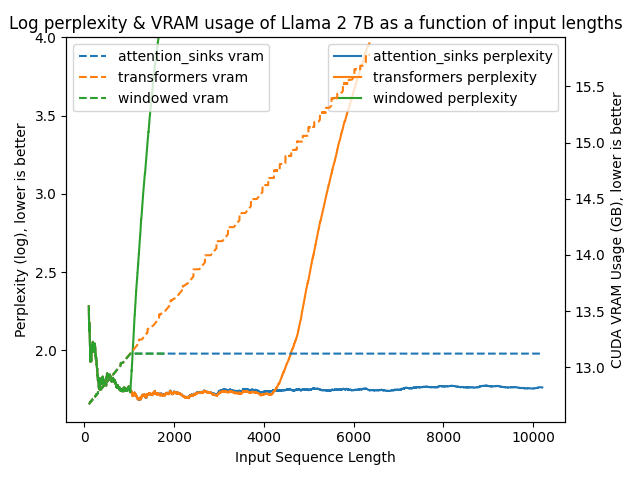
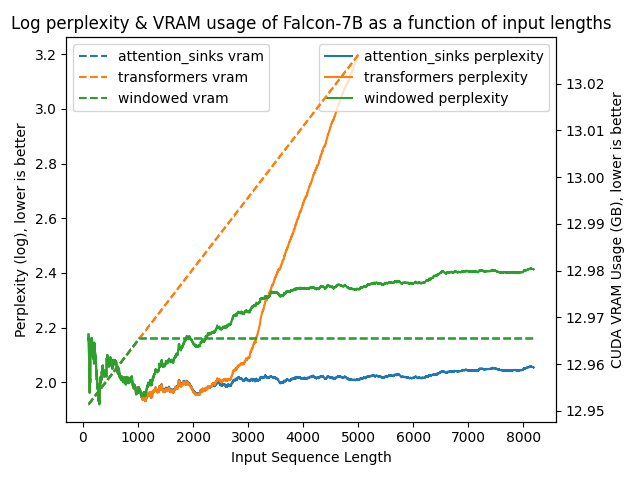
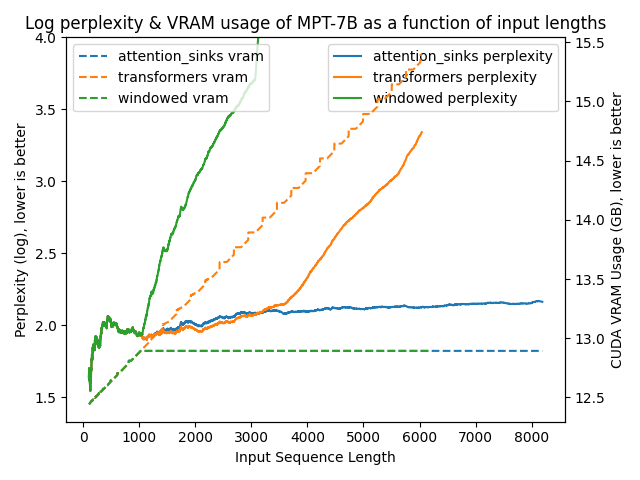
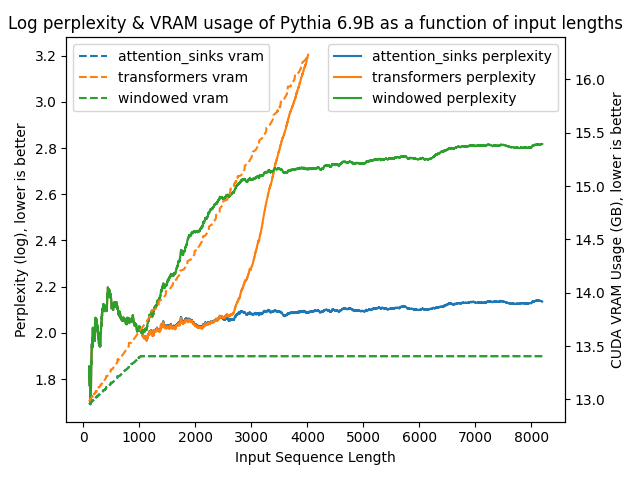
python benchmark/plot_perplexity.py --features perplexity vram --title "Log perplexity & VRAM usage of Llama 2 7B as a function of input lengths" --output_dir benchmark/outputs_llama_2_7b --log_perplexity_limit 4
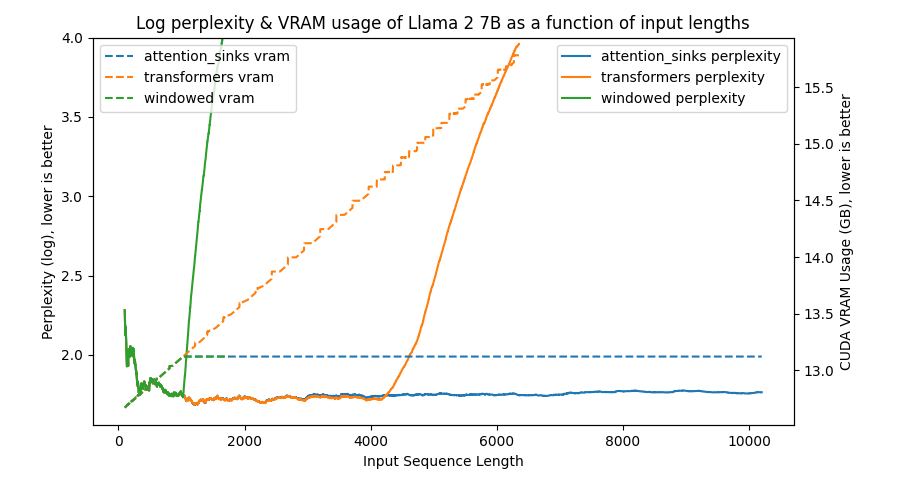
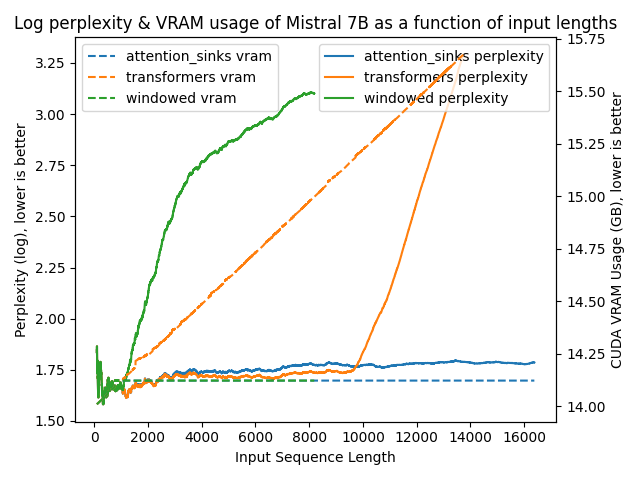
Clear as day:
transformers: The VRAM usage is linear as it doesn't do any windowing. The performance heavily falls after ~4096 tokens.windowed: The VRAM is constant usage due to the windowing at 1024 tokens. However, it fails as soon as the first tokens leave the window.attention_sinks: Constant VRAM usage due to windowing with 4 attention sink tokens + the 1020 most recent tokens. This approach never fails despite the constant VRAM usage.
I've uploaded outputs of various benchmarks in benchmark so you can reproduce this graph using the former command.
Changelog
See CHANGELOG.md for all release information.
Credits
Inspired by, and adapted from StreamingLLM.
Citation
@article{xiao2023streamingllm,
title={Efficient Streaming Language Models with Attention Sinks},
author={Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike},
journal={arXiv},
year={2023}
}


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Hashes for attention_sinks-0.2.2-py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 9a74bb51f4900c7fe096d25ecff326ccb2ebeb57906601d82a5d743f01857c9a |
|
| MD5 | f2c3282a49e1fe0088a28b597f63a059 |
|
| BLAKE2b-256 | 9f18e785e18b87033fcc2df8c16a1ff308758bd8c4ef2a6106b39f8f23a423b6 |







