Easy way to efficiently run 100B+ language models without high-end GPUs



Project description
Run 100B+ language models at home, BitTorrent-style.
Fine-tuning and inference up to 10x faster than offloading


Generate text using distributed 176B-parameter BLOOM or BLOOMZ and fine-tune them for your own tasks:
from petals import DistributedBloomForCausalLM
model = DistributedBloomForCausalLM.from_pretrained("bigscience/bloom-petals", tuning_mode="ptune", pre_seq_len=16)
# Embeddings & prompts are on your device, BLOOM blocks are distributed across the Internet
inputs = tokenizer("A cat sat", return_tensors="pt")["input_ids"]
outputs = model.generate(inputs, max_new_tokens=5)
print(tokenizer.decode(outputs[0])) # A cat sat on a mat...
# Fine-tuning (updates only prompts or adapters hosted locally)
optimizer = torch.optim.AdamW(model.parameters())
for input_ids, labels in data_loader:
outputs = model.forward(input_ids)
loss = cross_entropy(outputs.logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
🔏 Your data will be processed by other people in the public swarm. Learn more about privacy here. For sensitive data, you can set up a private swarm among people you trust.
Connect your GPU and increase Petals capacity
Run this in an Anaconda env (requires Linux and Python 3.7+):
conda install pytorch pytorch-cuda=11.7 -c pytorch -c nvidia
pip install -U petals
python -m petals.cli.run_server bigscience/bloom-petals
Or use our Docker image (works on Linux, macOS, and Windows with WSL2):
sudo docker run -p 31330:31330 --ipc host --gpus all --volume petals-cache:/cache --rm \
learningathome/petals:main python -m petals.cli.run_server bigscience/bloom-petals --port 31330
📚 See FAQ to learn how to configure the server to use multiple GPUs, address common issues, etc.
You can also host BLOOMZ, a version of BLOOM fine-tuned to follow human instructions in the zero-shot regime — just replace bloom-petals with bloomz-petals.
🔒 Hosting a server does not allow others to run custom code on your computer. Learn more about security here.
💬 If you have any issues or feedback, let us know on our Discord server!
Check out tutorials, examples, and more
Basic tutorials:
- Getting started: tutorial
- Prompt-tune BLOOM to create a personified chatbot: tutorial
- Prompt-tune BLOOM for text semantic classification: tutorial
Useful tools and advanced guides:
- Chatbot web app (connects to Petals via an HTTP endpoint): source code
- Monitor for the public swarm: source code
- Launch your own swarm: guide
- Run a custom foundation model: guide
Learning more:
📋 If you build an app running BLOOM with Petals, make sure it follows the BLOOM's terms of use.
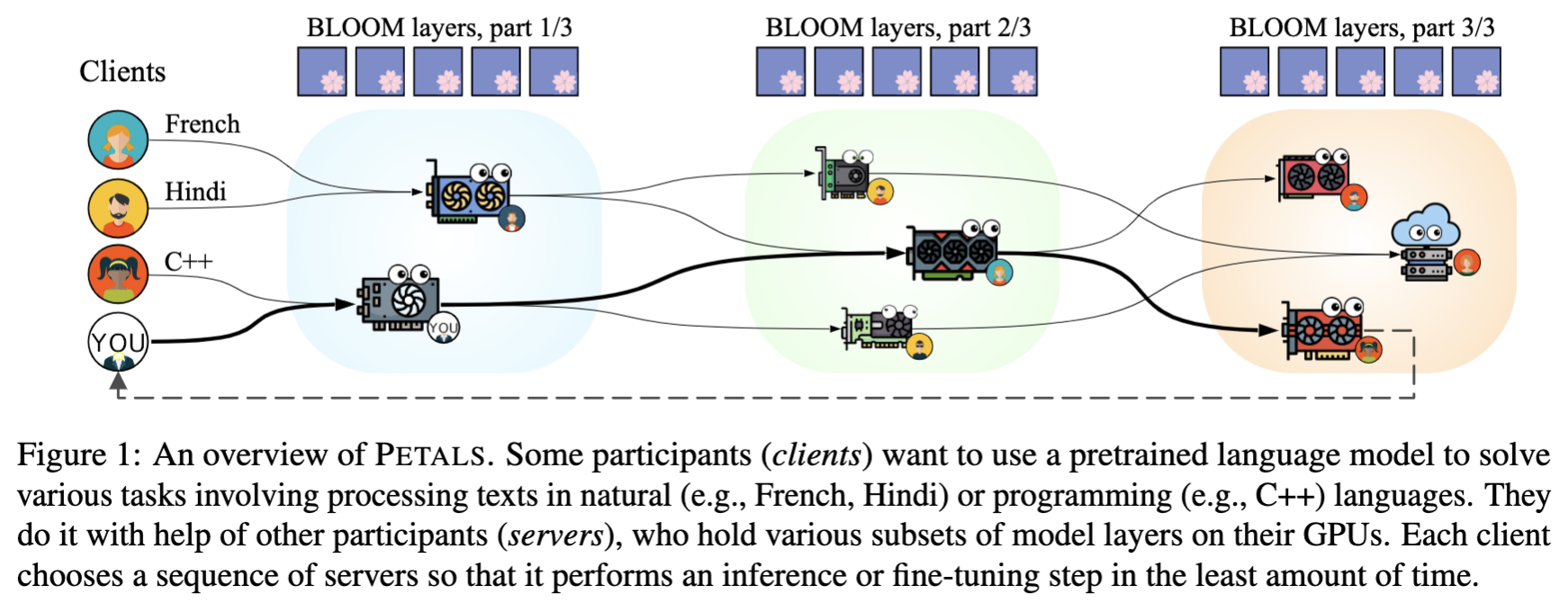
How does it work?
- Petals runs large language models like BLOOM-176B collaboratively — you load a small part of the model, then team up with people serving the other parts to run inference or fine-tuning.
- Inference runs at ≈ 1 sec per step (token) — 10x faster than possible with offloading, enough for chatbots and other interactive apps. Parallel inference reaches hundreds of tokens/sec.
- Beyond classic language model APIs — you can employ any fine-tuning and sampling methods by executing custom paths through the model or accessing its hidden states. You get the comforts of an API with the flexibility of PyTorch.
📚 See FAQ 📜 Read paper
Installation
Here's how to install Petals with conda:
conda install pytorch pytorch-cuda=11.7 -c pytorch -c nvidia
pip install -U petals
This script uses Anaconda to install CUDA-enabled PyTorch. If you don't have anaconda, you can get it from here. If you don't want anaconda, you can install PyTorch any other way. If you want to run models with 8-bit weights, please install PyTorch with CUDA 11 or newer for compatility with bitsandbytes.
System requirements: Petals only supports Linux for now. If you don't have a Linux machine, consider running Petals in Docker (see our image) or, in case of Windows, in WSL2 (read more). CPU is enough to run a client, but you probably need a GPU to run a server efficiently.
🛠️ Development
Petals uses pytest with a few plugins. To install them, run:
conda install pytorch pytorch-cuda=11.7 -c pytorch -c nvidia
git clone https://github.com/bigscience-workshop/petals.git && cd petals
pip install -e .[dev]
To run minimalistic tests, you need to make a local swarm with a small model and some servers. You may find more information about how local swarms work and how to run them in this tutorial.
export MODEL_NAME=bloom-testing/test-bloomd-560m-main
python -m petals.cli.run_server $MODEL_NAME --block_indices 0:12 \
--identity tests/test.id --host_maddrs /ip4/127.0.0.1/tcp/31337 --new_swarm &> server1.log &
sleep 5 # wait for the first server to initialize DHT
python -m petals.cli.run_server $MODEL_NAME --block_indices 12:24 \
--initial_peers SEE_THE_OUTPUT_OF_THE_1ST_PEER &> server2.log &
tail -f server1.log server2.log # view logs for both servers
Then launch pytest:
export MODEL_NAME=bloom-testing/test-bloomd-560m-main REF_NAME=bigscience/bloom-560m
export INITIAL_PEERS=/ip4/127.0.0.1/tcp/31337/p2p/QmS9KwZptnVdB9FFV7uGgaTq4sEKBwcYeKZDfSpyKDUd1g
PYTHONPATH=. pytest tests --durations=0 --durations-min=1.0 -v
After you're done, you can terminate the servers and ensure that no zombie processes are left with pkill -f petals.cli.run_server && pkill -f p2p.
The automated tests use a more complex server configuration that can be found here.
Code style
We use black and isort for all pull requests.
Before committing your code, simply run black . && isort . and you will be fine.
📜 Citation
Alexander Borzunov, Dmitry Baranchuk, Tim Dettmers, Max Ryabinin, Younes Belkada, Artem Chumachenko, Pavel Samygin, and Colin Raffel. Petals: Collaborative Inference and Fine-tuning of Large Models. arXiv preprint arXiv:2209.01188, 2022.
@article{borzunov2022petals,
title = {Petals: Collaborative Inference and Fine-tuning of Large Models},
author = {Borzunov, Alexander and Baranchuk, Dmitry and Dettmers, Tim and Ryabinin, Max and Belkada, Younes and Chumachenko, Artem and Samygin, Pavel and Raffel, Colin},
journal = {arXiv preprint arXiv:2209.01188},
year = {2022},
url = {https://arxiv.org/abs/2209.01188}
}
This project is a part of the BigScience research workshop.

Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.







