Easy way to efficiently run 100B+ language models without high-end GPUs



Project description
Run large language models at home, BitTorrent-style.
Fine-tuning and inference up to 10x faster than offloading


Generate text with distributed LLaMA 2 (70B, 70B-Chat), LLaMA-65B, Guanaco-65B or BLOOM-176B and fine‑tune them for your own tasks — right from your desktop computer or Google Colab:
from transformers import AutoTokenizer
from petals import AutoDistributedModelForCausalLM
model_name = "enoch/llama-65b-hf"
# You can also use "meta-llama/Llama-2-70b-hf", "meta-llama/Llama-2-70b-chat-hf",
# "bigscience/bloom", or "bigscience/bloomz"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoDistributedModelForCausalLM.from_pretrained(model_name)
# Embeddings & prompts are on your device, transformer blocks are distributed across the Internet
inputs = tokenizer("A cat sat", return_tensors="pt")["input_ids"]
outputs = model.generate(inputs, max_new_tokens=5)
print(tokenizer.decode(outputs[0])) # A cat sat on a mat...
🦙 Want to run LLaMA 2? Request access to its weights at the ♾️ Meta AI website and 🤗 Model Hub, then run huggingface-cli login in the terminal before loading the model. Or just try it in our chatbot app.
📋 Terms of use. Make sure you follow the model license (see the ones for LLaMA 2, LLaMA and BLOOM).
🔏 Privacy. Your data will be processed by other people in the public swarm. Learn more about privacy here. For sensitive data, you can set up a private swarm among people you trust.
Connect your GPU and increase Petals capacity
Petals is a community-run system — we rely on people sharing their GPUs. You can check out available servers on our swarm monitor and connect your GPU to help serving one of the models!
🐍 Linux + Anaconda. Run these commands:
conda install pytorch pytorch-cuda=11.7 -c pytorch -c nvidia
pip install git+https://github.com/bigscience-workshop/petals
python -m petals.cli.run_server enoch/llama-65b-hf --adapters timdettmers/guanaco-65b
🪟 Windows + WSL. Follow the guide on our Wiki.
🐋 Any OS + Docker. Run our Docker image:
sudo docker run -p 31330:31330 --ipc host --gpus all --volume petals-cache:/cache --rm learningathome/petals:main \
python -m petals.cli.run_server --port 31330 enoch/llama-65b-hf --adapters timdettmers/guanaco-65b
These commands host a part of LLaMA-65B with optional Guanaco adapters on your machine. You can also host meta-llama/Llama-2-70b-hf, meta-llama/Llama-2-70b-chat-hf, bigscience/bloom, bigscience/bloomz, and other compatible models from 🤗 Model Hub, or add support for new model architectures.
🦙 Want to host LLaMA 2? Request access to its weights at the ♾️ Meta AI website and 🤗 Model Hub, generate an 🔑 access token, then use this command for petals.cli.run_server:
python -m petals.cli.run_server meta-llama/Llama-2-70b-chat-hf --token YOUR_TOKEN_HERE
💬 FAQ. Check out our Wiki to learn how to use multple GPUs, restart the server on reboot, etc. If you have any issues or feedback, ping us in our Discord!
🔒 Security. Hosting a server does not allow others to run custom code on your computer. Learn more here.
🏆 Thank you! Once you load and host 10+ blocks, we can show your name or link on the swarm monitor as a way to say thanks. You can specify them with --public_name YOUR_NAME.
Check out tutorials, examples, and more
Basic tutorials:
- Getting started: tutorial
- Prompt-tune LLaMA-65B for text semantic classification: tutorial
- Prompt-tune BLOOM to create a personified chatbot: tutorial
Useful tools and advanced guides:
- Chatbot web app (connects to Petals via an HTTP/WebSocket endpoint): source code
- Monitor for the public swarm: source code
- Launch your own swarm: guide
- Run a custom foundation model: guide
Learning more:
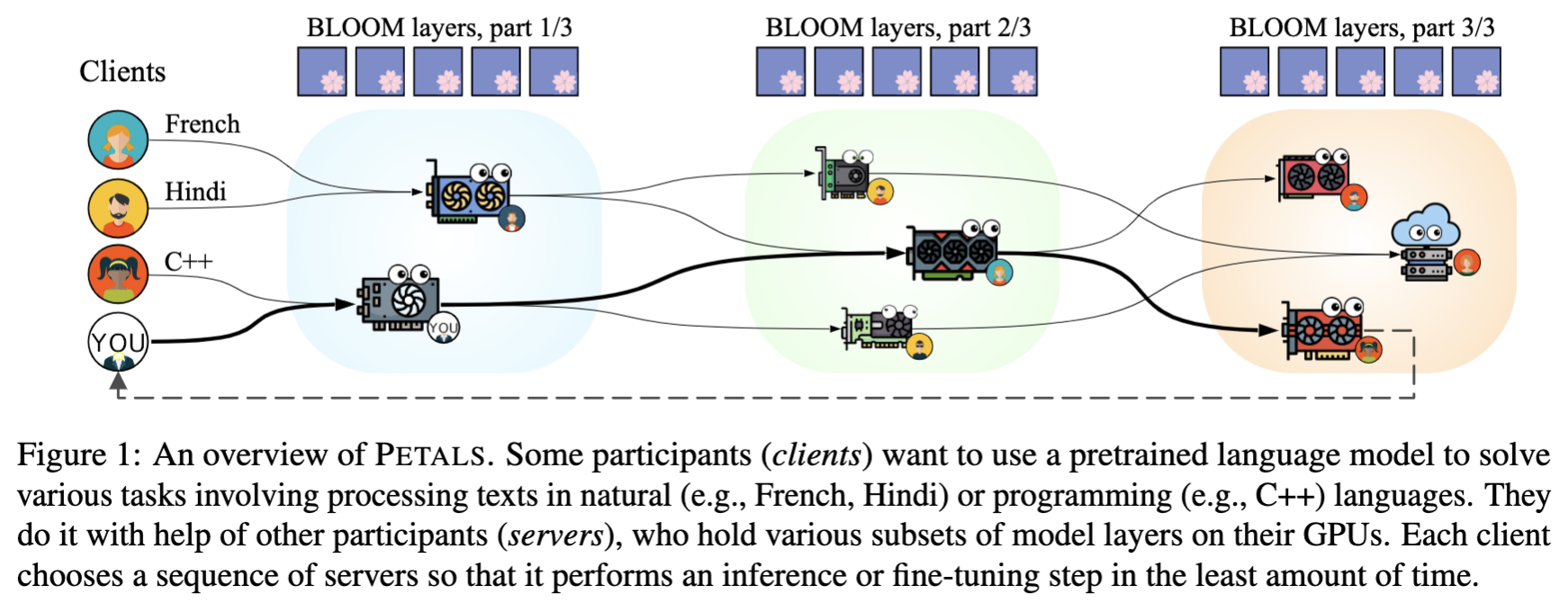
How does it work?
- Petals runs large language models like LLaMA and BLOOM collaboratively — you load a small part of the model, then team up with people serving the other parts to run inference or fine-tuning.
- Single-batch inference runs at up to 6 steps/sec for LLaMA 2 (70B) and ≈ 1 step/sec for BLOOM-176B. This is up to 10x faster than offloading, enough for chatbots and other interactive apps. Parallel inference reaches hundreds of tokens/sec.
- Beyond classic language model APIs — you can employ any fine-tuning and sampling methods, execute custom paths through the model, or see its hidden states. You get the comforts of an API with the flexibility of PyTorch.
📚 See FAQ 📜 Read paper
Installation
Here's how to install Petals with Anaconda on Linux:
conda install pytorch pytorch-cuda=11.7 -c pytorch -c nvidia
pip install git+https://github.com/bigscience-workshop/petals
If you don't use Anaconda, you can install PyTorch in any other way. If you want to run models with 8-bit weights, please install PyTorch with CUDA 11.x or newer for compatility with bitsandbytes.
See the instructions for macOS and Windows, the full requirements, and troubleshooting advice in our FAQ.
Benchmarks
The benchmarks below are for BLOOM-176B:
| Network | Single-batch inference (steps/s) |
Parallel forward (tokens/s) |
|||
|---|---|---|---|---|---|
| Bandwidth | Round-trip latency |
Sequence length | Batch size | ||
| 128 | 2048 | 1 | 64 | ||
| Offloading, max. possible speed on 1x A100 1 | |||||
| 256 Gbit/s | 0.18 | 0.18 | 2.7 | 170.3 | |
| 128 Gbit/s | 0.09 | 0.09 | 2.4 | 152.8 | |
| Petals on 14 heterogeneous servers across Europe and North America 2 | |||||
| Real world | 0.83 | 0.79 | 32.6 | 179.4 | |
| Petals on 3 servers, with one A100 each 3 | |||||
| 1 Gbit/s | < 5 ms | 1.71 | 1.54 | 70.0 | 253.6 |
| 100 Mbit/s | < 5 ms | 1.66 | 1.49 | 56.4 | 182.0 |
| 100 Mbit/s | 100 ms | 1.23 | 1.11 | 19.7 | 112.2 |
1 An upper bound for offloading performance. We base our offloading numbers on the best possible hardware setup for offloading: CPU RAM offloading via PCIe 4.0 with 16 PCIe lanes per GPU and PCIe switches for pairs of GPUs. We assume zero latency for the upper bound estimation. In 8-bit, the model uses 1 GB of memory per billion parameters. PCIe 4.0 with 16 lanes has a throughput of 256 Gbit/s, so offloading 176B parameters takes 5.5 seconds. The throughput is twice as slow (128 Gbit/s) if we have two GPUs behind the same PCIe switch.
2 A real-world distributed setting with 14 servers holding 2× RTX 3060, 4× 2080Ti, 2× 3090, 2× A4000, and 4× A5000 GPUs. These are personal servers and servers from university labs, spread across Europe and North America and connected to the Internet at speeds of 100–1000 Mbit/s. 4 servers operate from under firewalls.
3 An optimistic setup that requires least communication. The client nodes have 8 CPU cores and no GPU.
We provide more evaluations and discuss these results in more detail in Section 3.3 of our paper.
🛠️ Contributing
Please see our FAQ on contributing.
📜 Citation
Alexander Borzunov, Dmitry Baranchuk, Tim Dettmers, Max Ryabinin, Younes Belkada, Artem Chumachenko, Pavel Samygin, and Colin Raffel. Petals: Collaborative Inference and Fine-tuning of Large Models. arXiv preprint arXiv:2209.01188, 2022.
@article{borzunov2022petals,
title = {Petals: Collaborative Inference and Fine-tuning of Large Models},
author = {Borzunov, Alexander and Baranchuk, Dmitry and Dettmers, Tim and Ryabinin, Max and Belkada, Younes and Chumachenko, Artem and Samygin, Pavel and Raffel, Colin},
journal = {arXiv preprint arXiv:2209.01188},
year = {2022},
url = {https://arxiv.org/abs/2209.01188}
}
This project is a part of the BigScience research workshop.

Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.







