Saves plots as PDF with embedded generating script

Project description
Overview
The pypdfplot package is an extension to Matplotlib that generates a PDF file of the plot with the generating Python script embedded.
Although Matplotlib is a very powerful and flexible plotting tool, once a plot is saved as PNG or PDF file, the link between the plot and its generating Python script is lost. The philosophy behind pypdfplot is that there should be no distinction between the Python script that generates a plot and its output PDF file, much like there is no such distinction in an Origin or Excel file. As far as pypdfplot is concerned, the generating script is the plot.
The way pypdfplot works is by extending Matplotlib with a publish function. This function saves the current plot as a PDF file and embeds the generating Python script in that PDF file. The Python script is embedded in such a way that when the PDF file is renamed from .pdf to .py, the file can be read by a Python interpreter without alteration. The script can then be edited at will to implement changes in the plot, after which the script is ran again to produce the updated PDF file of the plot – including the updated embedded generating script.
Since the resulting output file is compliant with both Python and PDF syntax, we will call such a file a PyPDF file for the remainder of this document.
Installation
Via Python Package
Install the package from the PyPI repository opening a command prompt and enter:
pip install pypdfplotVia Git or Download
Alternatively, the source files can be downloaded directly from the GitHub repository. After downloading the source files, navigate to the project directory and install the package by opening a command prompt and enter:
python setup.py installQuickstart
The pypdfplot package is designed to seamlessly integrate with Matplotlib. In this section we will go through a basic example that shows how to use pypdfplot.
Simple Example
For this example, our goal is to produce a red plot of the quadratic function from -10 to 20. To start off, we will first plot this in the conventional way using Matplotlib.
Create a new python file, let’s call it example.py.
Open the file and enter the following script:
import matplotlib.pyplot as plt
import numpy as np
x = np.arange(-10,20,0.1)
y = x**2
plt.plot(x,y,'r')
plt.show()After running this script, we should get the following figure:

Next, we will use pypdfplot to publish this plot as a PyPDF file. In order to do this we need to make two changes to the script:
Instead of importing matplotlib.pyplot we have to import pypdfplot. Note that pypdfplot wraps all Matplotlib’s functions, so by importing pypdfplot as plt like before, no other modifications to the code are needed.
Instead of calling show() we have to call publish(). Note that publish() can take all keywords that show() can, in addition to some new keywords (see Classes).
The code now looks as follows:
import pypdfplot as plt
import numpy as np
x = np.arange(-10,20,0.1)
y = x**2
plt.plot(x,y,'r')
plt.publish()After running this script, if we look in the folder where our example.py file once was, we notice it has been replaced by a new file example.pdf. Of course the fact that the example.py file disappeared doesn’t mean the script is gone – it is now embedded in the PyPDF file example.pdf!
We can find evidence of this by opening the example.pdf file:

The table on the left shows all files that are embedded, and clearly example.py is there.
Most versions of Acrobat reader don’t allow the embedded .py file to be opened for security reasons, which is probably a good thing. To access the python script, rename example.pdf into example.py and open the file. This is what we should find:
#%PDF-1.3 23 0 obj << /Type /EmbeddedFile /Length 124 >> stream
import pypdfplot as plt
import numpy as np
x = np.arange(-10,20,0.1)
y = x**2
plt.plot(x,y,'r')
plt.publish()
"""
endstream
endobj
1 0 obj
<...>
startxref
8829
%%EOF
0000009410 00000
"""The first line is the PDF header that helps the PDF reader to determine this is a valid PDF file. It also includes the object header for the EmbeddedFile object of our example.py file. This line may not be altered, as it will result in corruption of the PyPDF file.
What follows is our original python script, followed by a massive multiline string. This multiline string contains all the PDF objects including the data for any remaining embedded files (see PyPDF File specification). Making any edits in this string will again likely result in corruption of the file, so it is strongly discouraged as well.
In between the first line and the multiline string is our original python script, which may be edited in any way. For example, let’s give the plot a title and change the color to blue:
#%PDF-1.3 23 0 obj << /Type /EmbeddedFile /Length 124 >> stream
import pypdfplot as plt
import numpy as np
x = np.arange(-10,20,0.1)
y = x**2
plt.plot(x,y,'b')
plt.title('Blue Example')
plt.publish()
"""
endstream
endobj
1 0 obj
<...>
startxref
8829
%%EOF
0000009410 00000
"""Again, after running the script the example.py file is replaced by the example.pdf file. When we open example.pdf, we should find the updated blue plot with caption:

publish() keywords
The behaviour of the publish function can be altered through the use of the following keywords. Default values are given in brackets.
output (str) default = None – Filename of the output file. If None, the filename of the python file is used with extension .pdf.
in_place (bool) default = True – Whether or not to perform the publication ‘in place’. If True, the Python file generating the plot will be deleted.
show_plot (bool) default = True – Whether or not to display the plot after publication.
prompt_overwrite (bool) default = False – Wether or not to prompt when the output file already exists and is about to be overwritten. If False and the output file does already exist, pypdfplot will overwrite the file if possible.
verbose (bool) default = True – Wether or not to show verbose comments during publication.
Embedding Files
In many cases we would like to plot data that is stored in a separate file. In order for this to work, the external data file must be included in the PyPDF file as well. What follows is an example how to embed external files with pypdfplot.
We will write a script that opens data from an external excel file and reads the title and axis label from an extrnal text file.
Create an excel file called data.xlsx. For this example, we will fill the file with the first 10 numbers of the Fibonacci sequence:
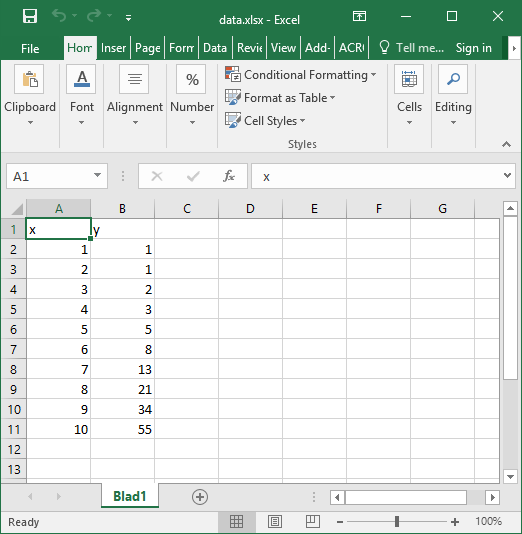
Then we create a text file with our title and axis labels called title.txt:
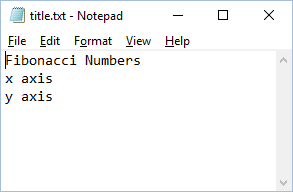
Finally, we create a new python file called packing.py.
As before, let’s first have a look at how this script would look using Matplotlib. We will use Pandas to import the Excel file into Python. Open packing.py and enter the following script:
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_excel('data.xlsx')
plt.plot(df.x,df.y,'r.')
with open('title.txt','r') as f:
title = f.readline()
xlabel = f.readline()
ylabel = f.readline()
plt.title(title)
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.show()After running this script, the following figure should pop up:

In order to use pyplotpdf to publish this as a PyPDF file, we change matplotlib.pyplot to pypdfplot and show() to publish() as before.
Additional files can be embedded in the PyPDF file by calling the function pack(flist). The argument flist is a list of filenames that are to be embedded.
By setting the keyword cleanup = True in the publish() function, the local files are deleted after they are successfully embedded in the PyPDF file.
The script now looks as follows:
import pypdfplot as plt
import pandas as pd
df = pd.read_excel('data.xlsx')
plt.plot(df.x,df.y,'r.')
with open('title.txt','r') as f:
title = f.readline()
xlabel = f.readline()
ylabel = f.readline()
plt.title(title)
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.pack(['data.xlsx',
'title.txt'])
plt.publish(cleanup = True)After running the script, the output file packing.pdf is generated and all three files packing.py, data.xlsx, and title.txt are deleted after being embedded in packing.pdf. This can be confirmed by opening packing.pdf:

To maximize integration with Matplotlib, the PyPDF file is checked for embedded files at the time the pypdfplot package is imported. If embedded files are found, they are extracted provided there are no local files with the same filename. If a local file is found with the same filename, it is assumed this is a more recent version (e.g. a file that was extracted and then updated), and should therefore have precedence over the embedded file.
In case you want to keep the files that are extracted from the PyPDF file, simply set the keyword cleanup = False (or omit).
Editing Embedded Files
There are two ways embedded files can be edited or updated: The Python way or the PDF way. The author encourages editing files via Python, but using PDF should also work.
The Python way
Exctract all embedded files from the PyPDF file by renaming the file to the .py extension, and running the Python script with the cleanup keyword function False (or omitted).
Edit the local file
Run again to embed the updated files. If so desired, the cleanup = True keyword can be used again to remove all local files.
When pypdfplot tries to exctract the outdated files from the pypdf file, it will check for local copies. If a local copy is present, it will assume it is a more recent version and will not extract the outdated embedded file.
The PDF way
In the PDF viewer (in most cases, this is Adobe Acrobat), double click on the embedded file you wish to edit to open it.
Edit the file and save it. It will be saved as a local copy in the PDF viewer.
Save the PDF file
Because the PDF file was saved by a viewer that is unaware of the PyPDF file format, the format is severed. Assuming your filename is pdf_file.pdf, run the following script to convert the PDF file back to PyPDF:
from pypdfplot import fix_pypdf
fix_pypdf('pdf_file.pdf')PyPDF File specification
This document is work in progress
The file generated by pypdfplot is both a PDF file and a Python file. It would be more accurately to describe it as the intersection of both speficifications, i.e. a PyPDF file.
A PyPDF file can come in either Class I or Class II:
Class I
A PyPDF file that is unedited, and therefore compliant with both PDF and Python file specification.
Class II-A
A PyPDF file that has been saved (likely after edits) by a Python editor. It should be expected that the offsets in the xref table and the xrefstart address are not pointing to the right locations anymore. The filesize entry in the trailer must still be at the second to last line in order to qualify as Class II-A. It is assumed that only the Python script has been edited, so the offset difference can be retrieved from the difference between the filesize entry and the actual filesize.
Class II-B
A PyPDF file that has been saved (possibly after edits) by a PDF writer. The ‘#’ at the start of the file will be absent and the generating script may not appear first in the file anymore and could be encoded. The filesize entry will also be absent, but the offsets in xref table will still be correct. This file can therefore not be read by a Python interpreter. The file can be restored to Class I by retrieving its Python script via the /PyFile key in the trailer. This fix can be applied by running pypdf_fix <filename.pdf>.
A PyPDF compliant reader must be able to read Class I, Class II-A, and Class II-B files. A PyPDF compliant writer may only write Class I files.
Functions
This document is work in progress
Description of the functions
Classes
This document is work in progress
Description of the two classes
Changelog
Here we list all changes
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Hashes for pypdfplot-0.5.1-py2.py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 1d225dbbda3c8d1faa8ed64366b7426e7ea6374df10d175978d131b4b992ffb3 |
|
| MD5 | b0cffb49abbd39008f0e8c262f5dce3b |
|
| BLAKE2b-256 | ac6b9aa04b30d8f0fd136515b4c54b92c31883adf812a766b6d9e5cb53d673a7 |







